
Today we’ll look at backgrounder topologies. Do you go big or small with your machines and how many backgrounder processes do you deploy to them?
This is the part where we get serious. You might want to review this thing and this other thing which are lead-ins.
Under-burdened, Burdened, and Over-burdened
First, let’s define some terms I just made up. These may not be the best way to describe the scenarios I’m about to lay out, but such is life.
As you already know, Tableau support recommends that you take the core count of a dedicated backgrounder machine and divide by two to calculate how many backgrounder processes to run on it.
In other words, on a 16 vCPU (8 core) instance, I’ll be running 4 backgrounder processes. What does CPU Utilization look like on machines matching this description which are constantly refreshing extracts? Funny you should ask:
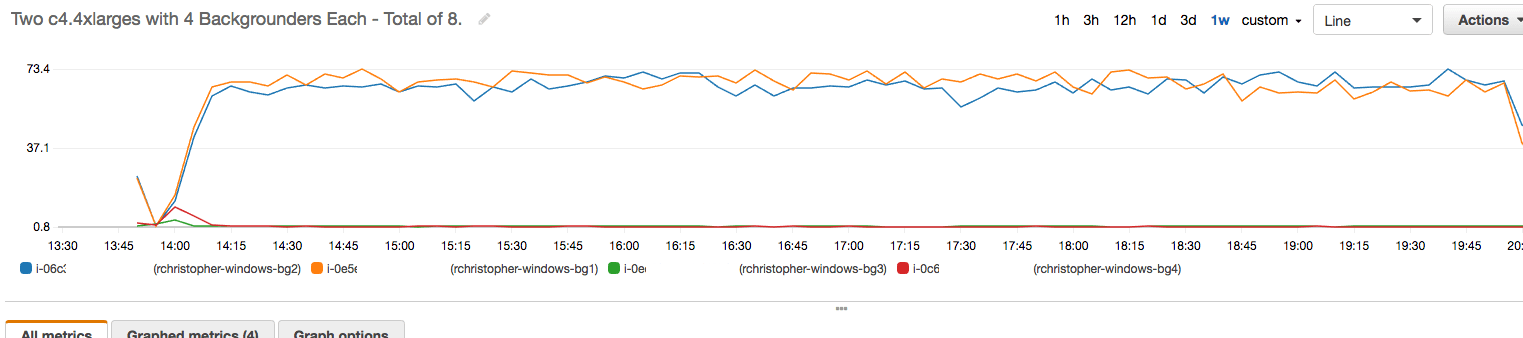
The two machines above are running around 70% CPU utilization. Nice and healthy. Support knows what they’re talking about!
We’ll call this an under-burdened machine. It’s working, maybe even sweating a little, but it can do more.
Let’s double the number of backgrounders from .5 per core to 1 per core. We’ll call this a burdened machine. Here are the same c4.4xlarge rigs executing the same workload, but running 8 backgrounders each for a total of 16:

95%+ CPU Utilization all the time. This is like me when I’m hauling my ass up some of the hills here in Seattle on my brand new bicycle.
I’m hurting.
Finally, let’s triple the number of backgrounders from .5 per core to 1.5 per core. That’s 12 backgrounders on each of our eight core machines when we’re running in over-burdened mode:

We’ve completely pegged the CPU. This is like me riding up those same damn hills when the wind is against me…which happens every other day or so. Yes. I’m bitter.
Rule #1
As I’m sure you’ve already guessed, the more backgrounders we provision on a box, the more refreshing work we’ll be able to get done:
MOAR BACKGROUNDERS = TPS
– Sun Tzu
Even if I’m the fastest sandwich maker in the West, it’s likely that my two or three assistant sandwich elves can together push out more food than I can.
Let’s take a quick look at TPS for the two c4.4xlarge backgrounders I just showed you CPU Utilization values for. You won’t be surprised since you are well-read and know Sun Tzu’s thoughts on the subject. More backgrounders = higher TPS (until the CPU or some other resource on the machine becomes saturated):
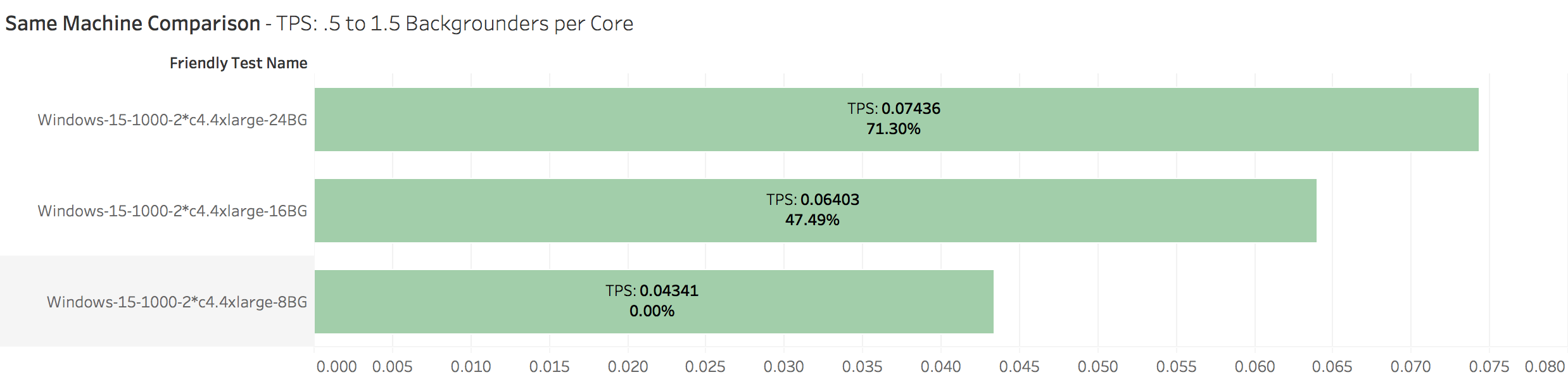
Burdened machines delivered 47% more TPS than our “conventional wisdom” .5 backgrounders-per-core under-burdened rigs. Overburdened machines pushed 71% more TPS.
And that’s not all.
Because we’re running more backgrounders, we’re going to get through the queue of jobs waiting to be processed faster. Here’s the same chart above, but I’ve included average wait time per job (in minutes):
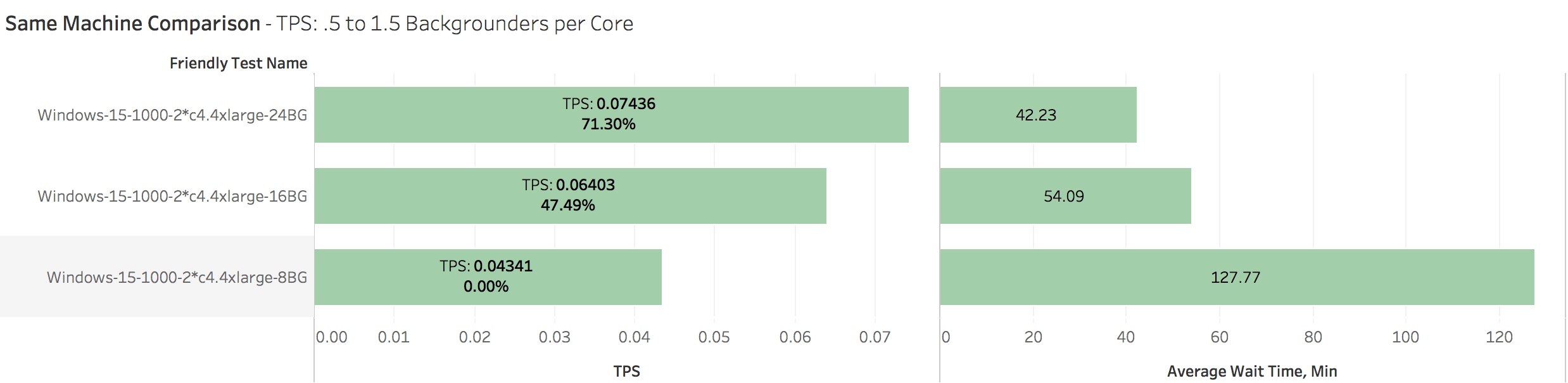
We’re looking at an average wait time of 3x on the under-burdened machine. That’s pretty major.
Rule #2
Generally, when you’re completely thrashing a machine like we are in the overburdened scenario, you should expect the individual runtime of each extract refresh to be higher – there’s simply more competition for resources. Again, here are our two (eight core) c4.4xlarges at work:

Nothing is free in this world, and you can see how we’re paying. Based on your workload you’re going to need to engage in a little dance in which you attempt to provision the most backgrounders you can (to increase parallelism) while NOT completely killing your runtime. It’s fun!
Here’s a view of only the x-small workbooks, which I mentioned are the ones I theoretically care the most about. Realistically, my users probably aren’t going to notice the difference between a 30s un-burdened refresh and a 50-60s over-burdened refresh. They WILL notice the 42 vs. 127 minute queue time however.

So, for this workload ignoring the .5 backgrounder/core advice of our fine friends in technical support might not be a bad thing. I’m going to purposefully blast my dedicated backgrounder machines with what some would consider too many backgrounder processes.
Choosing between horizontal and vertical scaling
Not to put too fine a point on it, but….

Again, we’re only talking about one specific workload today. That said, I’ve seen this often enough that I feel comfortable making it my general rule of thumb.
TPS
Lets start by looking at TPS on the C4. We’ll leverage (Over/Under/Burdened) clusters which utilize the same number of cores, but we’ll split those cores out in different ways:
- Four 4-core C4s = 16 Cores
- Two 8-core C4s = 16 Cores
- One 16-core C4 = 16 Cores

In all (Over/Under/Burdened) scenarios, the single c4.8xlarge with 16 cores was the laggard. It delivered somewhere between 10-23% less TPS than using four c4.2xlarge (4 core) machines based on the number of backgrounder processes I ran.
The two 8-core c4.4xlarge machines delivered:
- The same TPS as four 4-cores while “overburdened”
- Were a touch better while “burdened”
- About 6% worse in terms of TPS on under-burdened workloads than using more, smaller machines
(Yes, I know our documentation and Support say not to run on 4-core boxes. I’m just showing you what I see when it comes to this particular scenario around extract refreshing. Don’t apply it elsewhere, please!)
What about the M4? Pretty much the same deal.
I actually got sick and tired of testing not too far into these final runs, so I didn’t “complete” the matrix with all combinations of scenarios. (Not) Sorry.
The interesting thing here is that for the “big” machine, I actually used an m4.10xlarge, which is a 40 vCPU / 20-core instance. So machine is theoretically more powerful than the 16-core c4.8xlarge (at least in terms of cores and RAM. The c4.8xlarge still delivers more ECU)
Here’s the CPU utlization for that “big” m4.10xlarge during a run, btw:

Pegged at 100%, so it looks like we’re running on all cylinders.
The TPS results:

So I thought this was pretty cool – even with less cores, those four little m4.2xlarges did a better job than their big brother. They also were marginally better than two 8-core m4.4xlarges in terms of TPS. Small is good!
Runtime
More of the same when it comes to the individual execution time of different extract types.
In essence, smaller was better.
In the trellis below, I use my four (4-core) c4.xlarges as a baseline. If you see a negative value in the a label, it means that it was faster than the base scenario. A positive number indicates that this combination delivered x% less TPS:
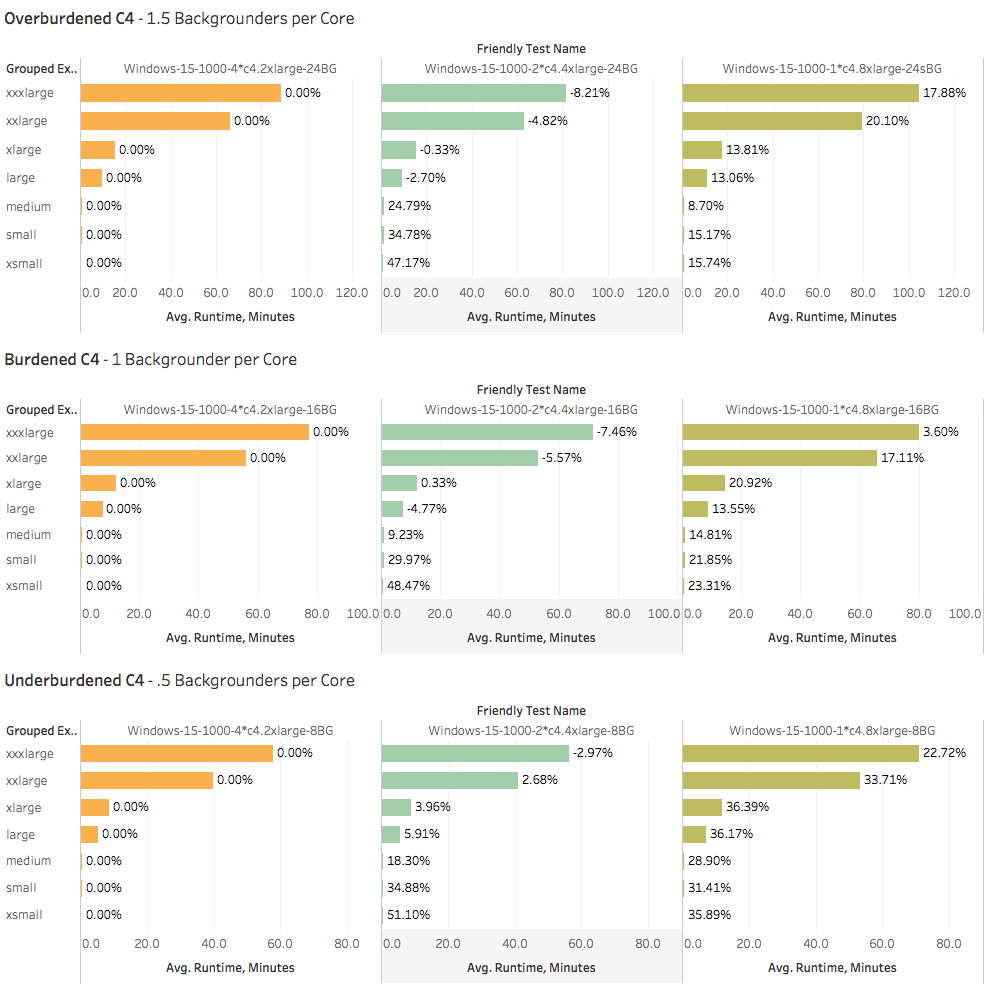
As you can see, the “big” c4.8xlarge never has a chance. Both the 4*c4.2xlarge and 2*c4.4xlarge rigs merrily tap dance on it’s head. The 8xlarge is like Hodor without the charm.
What is interesting to me is that the extra “beef” on the 8-core machines make them marginally better at refreshing bigger extracts. There’s not a huge difference, but there is one. If I had to wager, I’d guess the extra RAM on the 4xlarges is responsible since this instance type IS light on RAM to begin with.
The smaller-but-more-numerous c4.2xlarges were best at refreshing small extracts, with margins up to 50%…
And of course, I should show you the M4 results since I expended the effort to check them out:
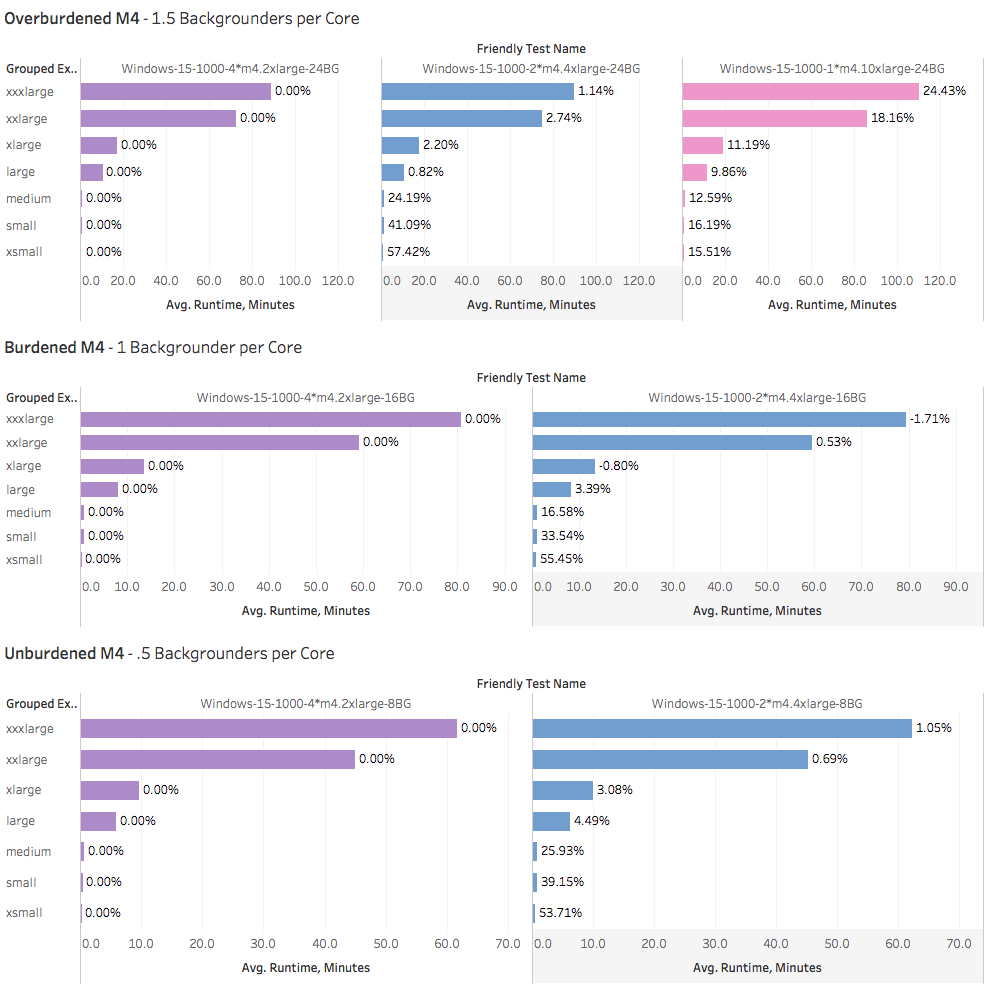
It seems that the two 8-core machines lose the small advantage they have over the four 4-core boxes when it comes to “big” extracts. Again, I think this may be because the M4s have 2x the RAM to begin with, so even the smallest of them never felt meaningful memory pressure — even with really large extracts.
I’m Pretty tired, I think I’ll go home now.
This was a long post and I’m ever-so-tired of typing. So I’m going to stop.
…but before I do, a summary:
Instance Types:
- C4s: Great
- M4s: Good
- R4s & I3’s: Not so good
Backgrounders:
- More backgrounders give higher TPS
- Conversely, more backgrounders tend to increase the runtime of individual extracts
- Choose a happy medium
Machine Sizes:
- Little: Great
- Medium: Good-Great
- Big: Not so good
BTW, Did you notice how all my tests were labeled with “Windows”? Why would a guy do that? Makes you think someone did some of the same work on a different operating system.
Very interesting stuff. I’ve seen similar things with 4 nodes systems. Unfortunately, I need support, so I’ve sworn off of them.
Looking forward to the information on the “other” OS. We’ve started testing, but not to the point of benchmarking yet.