
A few weeks ago, the AWS and Tableau teams released a new Quick Start: Modern Data Warehouse on AWS. We wanted to make it easy to deploy a validated data architecture that uses the services in question.
You know that I’m a sucker when it comes to Redshift. I’ve written all about making the two products work well together, so this is a topic near and dear to my heart. If you’re an old hand with CloudFormation, you can probably skim much of this. If you’re new to AWS and/or CloudFormation, you can use this post as a primer and avoid making newbie mistakes.
What’s in it?
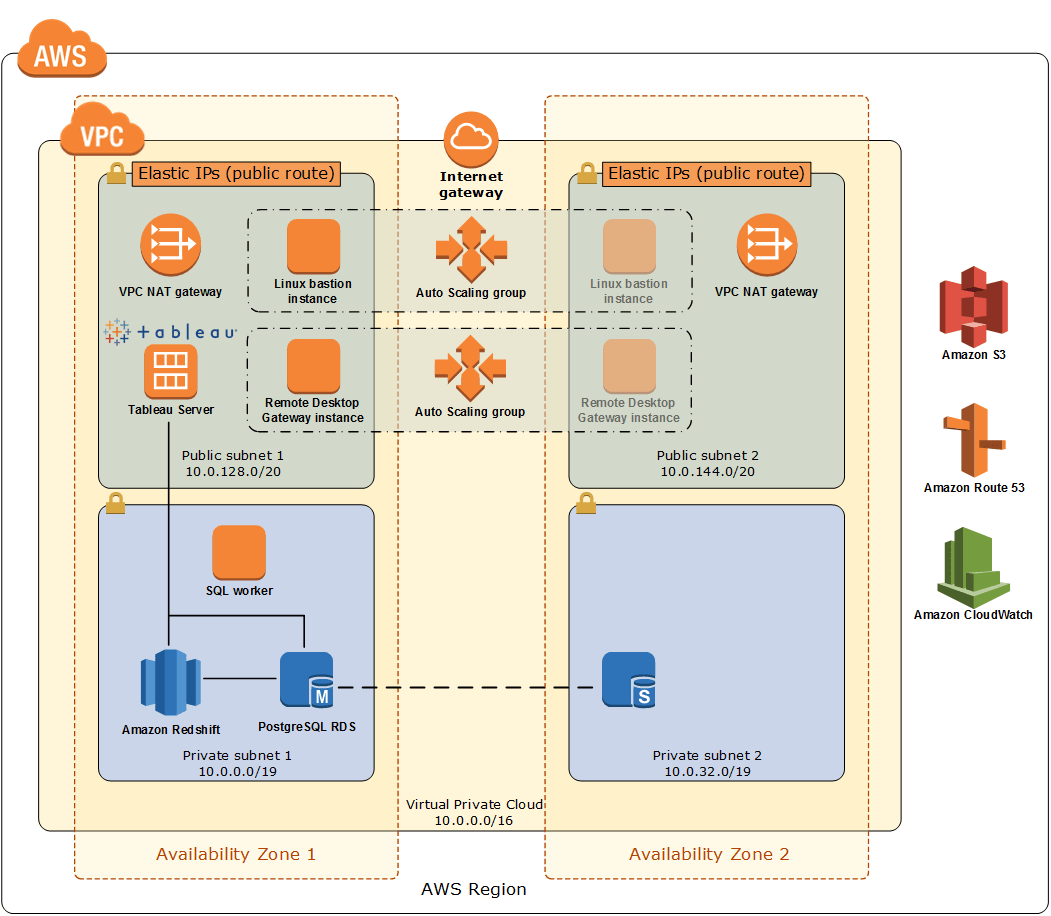
The main components of this Quick Start include:
- A Redshift Cluster sized however you’d like
- A Multi-AZ RDS (PostgreSQL) instance
- Tableau Server
The Quick Start also stands up a small (Linux) bastion host, a Microsoft Remote Desktop Gateway host, and another Linux instance used for executing “Setup SQL” against both Redshift and RDS.
Show me the data! Or not.
As an avid consumer of tutorials and walk-throughs, I’m often disappointed by the sample data I see. We went out of our way to create a robust dataset of about 200M rows which gets loaded into Redshift (or not) for you. You can also choose to plug in your own sample datasets instead. I think that is really cool, and the folks at 47Lining did a great job implementing this for us. Read more about the details here.
Here’s the thing: Loading ~200M rows of data takes a while. We’ll cover this more in depth later, but if you’re impatient, I’d recommend one of two things:
- Launch more Redshift nodes in order to take advantage of parallel COPYing and lower overall load time
- Turn data loading off altogether – not much fun afterwards, but will get the environment up fast if that’s all you want anyway
How does it work?
You’re looking at a CloudFormation template with data stored in S3. In essence, here’s what happens:
- (If necessary) A new VPC and associated network resources (subnets, NATs, etc.) are created for you
- Two Auto Scaling groups are created – one for the Remote Gateway host, one for the Linux Bastion. Both groups only launch a single instance “out of the box”
- The CloudFormation template launches a Redshift cluster and a Multi-AZ RDS (PostgreSQL engine)
- Tableau Server and a “SQL Worker” Linux instance are provisioned
- We publish a sample workbook to Tableau which utilizes “your” Redshift & RDS
- The SQL Worker executes SQL against PostgreSQL. It uses postgres_fdw to create a “link” with Redshift.
- The SQL Worker fires multiple statements at Redshift and PostgreSQL to create tables, views and COPY data into Redshift from S3
- The SQL Worker finishes off with a query against PostgreSQL which generates aggregates off the newly loaded data in Redshift via the foreign data wrapper
Specifying Stack Details
I want you love this stack, so here are few things to be aware of. It’s no fun to fill out Stack Details over and over again.
Before you begin, make sure you’ve already generated a key pair in the region you want to deploy in. You won’t be able to create it from inside the form.
After you’ve clicked the Deploy on AWS into a new VPC button on the Quick Start Page. You may or may not notice that the template defaults the AWS region to Ohio. Check the upper-right corner of your console… ![]() Don’t get me wrong, I love Ohio (NOT Ohio State, though – GO BLUE!), but you might want to switch this to something else – I’ll go to us-west-2 (Oregon):
Don’t get me wrong, I love Ohio (NOT Ohio State, though – GO BLUE!), but you might want to switch this to something else – I’ll go to us-west-2 (Oregon): ![]()
In the Specify Details screen, you can generally keep things as they are. Don’t forget to include two AZs in the Availability Zones parameter, however:

By default, Tableau Server Inbound CIDR is set to <VPCCIDR>. This means (among other things) that the Tableau Server machine will not accept requests over port 80 (HTTP) or 3389 (RDP) from the public internet. The CloudFormation template assigns a public ip address to Tableau Server, but it won’t do you any good because the security group created and applied to the instance will only allow traffic from inside the VPC to pass through on 80.
If you want to (easily) connect to Tableau Server from home or work, you should set this value to an appropriate CIDR. Below, I’m letting “the world” into my Server: It is sitting in a public subnet after all, and I’m just having fun:

w-w-What? Tableau Server in a public subnet: Is that right?
This Quick Start is focused on deploying data services in useful and correct way. It doesn’t really demonstrate best practices in terms of Tableau Server deployment (that can be found here) – we’re just giving you a server so you have something to point at RDS and Redshift. If I’m following “rules of the road” vis-a-vis running Tableau Server on AWS, I would change this template a bit:
– I’d stick the Tableau Server in a private subnet
– I’d put an ELB in front of Tableau Server
– I’d have Route 53 with an Alias Record pointing at the ELB
This would give me a much more secure Tableau Server and flexibility in terms of dealing with DDoS and DR scenarios.
When I’m just playing around, I let the whole world into my Bastion and Remote Desktop. You’ll want to restrict this to a particular subnet in production, but 0.0.0.0/0 is OK for now:

That key pair I told you to have handy? Don’t forget to plug it in.
You’ll be asked to enter a Remote Desktop Gateway Admin Password. Make sure it is complex enough. It needs to pass the standard rules of complexity on a password for a user in Windows – make SURE you use upper & lower case letters, a number, and a special character. This password needs to be more complex than the one you plug in for Redshift, RDS, and Tableau. This tripped me up once and the stack failed to create correctly because the RGDW didn’t like the password I provided.
How many nodes?

I mentioned before that the number of nodes you deploy will impact overall deployment time. That’s a bit of an understatement. We default to 2 nodes. If you go with that value, you can expect to be loading data into Redshift for at least an hour.
If you’re a patient saint, who cares: go for it. If you want to get to the good stuff as quickly as possible, I’d recommend you pump this up to 5+ nodes during the launch. You can always lower it via the Redshift console afterwards. For example, here I am running with three nodes, and you can see it still took me just slightly under an hour to complete my load:

This screencap represents the Performance page of the Redshift console. The red bar is the COPY action which loads data into Redshift. At about 25 minutes in, you can see the Tableau Server waking up and attempting to execute queries against our still-loading Redshift. At this point, the vizzes will return incomplete data. It’s not until around 9:35 and the final “blue queries” that everything is loaded and ready to go.
Another option you have is to simply turn data loading off altogether:

This selection will dramatically speed up your deployment. If you go this route, the sample dashboard deployed to Tableau won’t work, of course.
 When you finish filling in all the parameter boxes and click Next, you might also want to turn off CloudFormation’s Rollback on Failure default. You’ll find it by expanding the Advanced section of the page. Turning off rollback can be really useful in terms of troubleshooting deployment failures.
When you finish filling in all the parameter boxes and click Next, you might also want to turn off CloudFormation’s Rollback on Failure default. You’ll find it by expanding the Advanced section of the page. Turning off rollback can be really useful in terms of troubleshooting deployment failures.
WARNING: Nothing comes free – if you go this route, keep in mind you’ll be responsible for Deleteing this stack yourself if there’s a problem. If you forget, all the resources that have been provisioned up to the point of failure will keep running, costing you $$.
Don’t forget! I have. Several times.
Finally, remember to tick the I acknowledge… checkbox. If you neglect this step, CloudFormation won’t be able to create IAM roles necessary to deploy and secure all this good stuff for you. Your deployment will therefore fail.
![]()
Now, Wait.
How long does it take to deploy this sucker? It depends. As I mentioned, it took slightly less than an hour to load Redshift when running 3 nodes. WIth all the other stuff we do, the total wait time was about 1:40:

I said wait.
You will be tempted to start logging into machines and playing around before everything is done. Don’t. Several times I’ve lost self control and RDP-ed into Tableau Server during the automated install process. Depending on exactly when you login, you can break the automation if it hasn’t completed. Just leave it alone. Go dig a hole or sew some curtains or something.
Once the Tableau-with-AWS-Data (or whatever you’ve named your) parent stack shows CREATE_COMPLETE (see above), you’re ready to go.
Connecting to your stuff
If you’re curious about the coordination work that went on inside the SQL Worker, you can connect to it via your Bastion. Use ssh to connect to the bastion, then jump over to the SQL Worker:

You’ll find the IP address of your LinuxBastion in the IPv4 Public IP column of your EC2 instance list. The private IP of the SQL Worker that you “jump” to is on the Description tab of the SQLWorker instance: In my case it was 10.0.18.124.
You can find all this information by clicking the Output tab of the CloudFormation page and then selecting any Stack to see what it created. Below, I’ve selected the SQL Worker stack:

Next, we’ll connect to the Tableau Server via RDP. In order to do this, you need to know:
- The Windows Admin password of the Server running Tableau (use the “Connect” button when you’ve selected the instance)
- The Private IP address of the Windows Server
- The Public IP address of the Remote Desktop Gateway you’ll “jump” through to the Tableau Windows Server
(Or if you don’t care about RDP and logging into the Windows Server Desktop, get the Public IP Address of Tableau Server. This’ll let you hit the Server’s login page directly assuming you set Tableau Server Inbound CIDR to 0.0.0.0/0 as mentioned earlier)
Select the Tableau-with-AWS-DATA-RDGWStack item in your stack list, and note the Elastic IP associated with it: 35.167.45.105:
…that’s how you refer to your RDP gateway if you want to connect that way.
Next, select Tableau-with-AWS-Data-[ stuff ]-TableauServerStack-[stuff] stack at the very top of your list:

There’s lots of important information here:
- The Public IP address and/or DNSName that users can leverage to connect directly to Tableau Server via the browser (52.38.69.26 and ec2-52-38-69-26.us-west-2.compute.amazonaws.com)
- The Private IP address you can use to connect via RDP (10.0.131.143)
Who cares? What’s the payoff?
Why would you spend your precious time executing this template above and beyond the joy of learning? Let me explain, camper.
Redshift is really good at executing “big”, “expensive” queries against tables which contain billions of rows and many, many columns: Serena Williams sort of stuff.
Would you ask Serena to play doubles against you and your BFF from college? Nah, probably a waste of her time. She goes “all in” against a single opponent and (generally) destroys said challenger.
Same thing with Redshift. For the day-to-day work of powering “sales by month” and alike, a journey(wo)man opponent will do. Use RDS. Aggregate the data on a regular schedule and store it in RDS. Use RDS to power your day-to-day dashboards and analyses, and let Redshift do the Wonder Woman work.
Let me show you.
Tableau Sample Dashboards
The sample workbook which is published to Tableau Server essentially shows the same dashboard created two different ways. The first example has Redshift do everything (a waste of Serena). The second utilizes a mix of Serena and her slightly less powerful relative, RDS.
Below, I’ve logged into Tableau Server via the public DNS hostname that was assigned to it in the CloudFormation template. We’ll run the “Serena/Redshift” version of our dashboard. We’ll turn on Tableau’s performance recorder and make sure we’re not leaning on the cache by forcing all queries to re-execute. (Hi, Andy! your blog was the first that came up!):
![]()
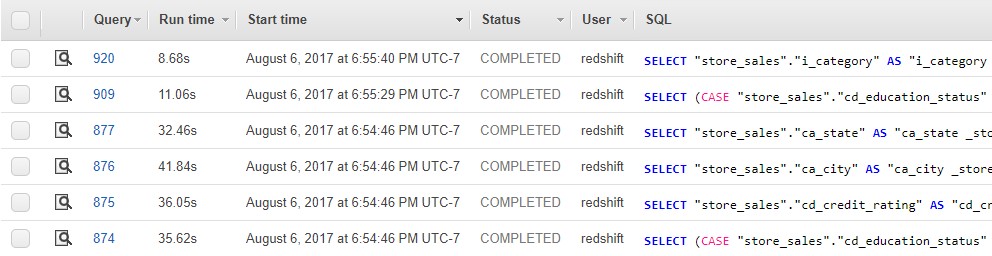
Here’s the result of said execution. Each and every sheet (and filter) in this dashboard connects to Serena (I mean Redshift) :

Here are the actual queries which were executed. We’re looking at the Queries page of the Redshift console:
Next, the Performance Recorder output for this dashboard:

In Events Sorted by Time, we see the same six queries (plus a wee bit of overhead) as in the Redshift console. Based on the order of execution and whether they fire in parallel, it took just about 63 seconds for the dashboard to render.
Next, let’s execute the same dashboard, but we’ll mix in a little bit of Serena with a whole lot of RDS. Again, we’ll turn on the performance recorder and ignore cache:
![]()
Here are the queries which were fired on Redshift. Notice the difference?:

The dashboard looks pretty much the same, although I used a very patriotic color palette:

….and finally…the Perf Recorder output:
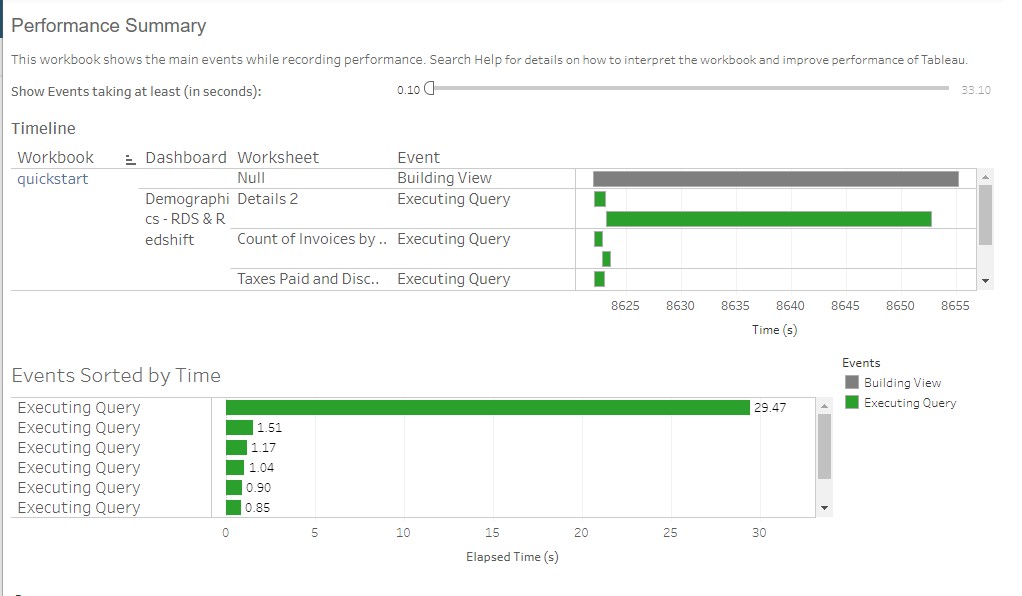
Even with all the power that Serena/Redshift can bring to bear on analytical queries, we were still smarter to lean on her little brother for some of the easier stuff. This dashboard came back in half the time: ~33 sec (on a 2-node Redshift cluster, no less).
Lessons Learned
(now I pitch you)
- Join the Unlock Insights and Reduce Costs by Modernizing Your Data Warehouse on AWS webinar on 22-Aug. We’ll have smart people there from Pearson, AWS, and Tableau
- Use the data services in AWS to mix-and-match your data services for best effect
- Play to the strengths of each service (RDS, Redshift). Data monocultures are boring
- It’s easy and fun to stand up your own environment with the Modern Data Warehouse on AWS Quick Start!
- 47Lining! Good!