
Holiday time is the most wonderful time of the year because I get to blog. A Lot. What better way to spend New Year’s day than banging out a really long post and making copious use of goofy clipart?
First, I assume you’ve read parts one and two of this series. If not, you probably should.
Below you’ll find the top ten (ish) things you should know about making Tableau and Redshift work well together. Some of the items are very straight forward — “Do this, don’t do that”. Other bits are a little more theoretical and will read like think piece. Don’t ignore them. I’ll call out specific tasks and nuggets to keep the theory actionable.
Work through this stuff, and in the next post I’ll actually put the guidance below into practice so you can see what it looks like in a “real world” scenario.
don’t just build Your Dashboard, Design it.
Did the folks at Apple decide to create the iPod, iPhone, and iPad one day and start building it the next? How do you think those devices would have turned out if they had? They would have delivered a brown Zune. Think before you do anything.
Don’t think like the guy putting up the sheetrock in your new house – think like the architect who drew up the plans in the first place. Knowing all about LOD calcs, parameters, and floating sheets is great. But, that stuff won’t help you if the house is falling down around you. Sheetrock won’t save the day.
 Task: Have you read and internalized Alan Eldridge’s Designing Efficient Workbooks white paper? I’ve asked before, but I’ll do so again because you need to. It isn’t specific to Redshift, but 85-90% of the material there applies directly to being successful with Tableau and Redshift. You need to invest time with this wisdom.
Task: Have you read and internalized Alan Eldridge’s Designing Efficient Workbooks white paper? I’ve asked before, but I’ll do so again because you need to. It isn’t specific to Redshift, but 85-90% of the material there applies directly to being successful with Tableau and Redshift. You need to invest time with this wisdom.
One of the things Alan writes about is keeping it simple – everything in moderation. This ties directly back to top ten item #4 (concurrency).
 Nugget: So, don’t put 7-10 vizzes in a dashboard and then add another 3-5 quick filters. Remember that we generally need to fire a query (sometimes more) for each viz and quick filter. This means you’ll likely fire 10-15 queries at Redshift, which won’t make it happy (concurrency). If Redshift isn’t happy, you won’t be happy.
Nugget: So, don’t put 7-10 vizzes in a dashboard and then add another 3-5 quick filters. Remember that we generally need to fire a query (sometimes more) for each viz and quick filter. This means you’ll likely fire 10-15 queries at Redshift, which won’t make it happy (concurrency). If Redshift isn’t happy, you won’t be happy.
Nugget: You should be aggressive with filters without using too many. Since Redshift has no indexes it needs to scan data. If you are smart about limiting the data you show in a dashboard and you use sort keys (Top Ten item # 7), you will scan WAY less data. That means faster query performance. Most new dashboard authors show data for “all time and categories” and then let the user filter down to something meaningful. You’re going to do the opposite. If you must show “all time” you’ll use some sort of a summary table (Top Ten item #8).
Nugget: Speaking of “being present” when you design something in Tableau…Did you know that LOD calcs are implemented via subqueries? These subqueries use INNER or (gasp!) CROSS JOINS. If you’re not “aware as you build”, you may inadvertently add more JOINs (Top Ten item #5) to the queries Tableau generates, which can cause substandard performance.
Learn about Redshift
What you don’t know can sometimes hurt you, right? Flora and fauna are cute in New Zealand, but will kill you in Australia.
You should invest time learning about Redshift. You need to know how it works and the basics of performance tuning. I’ll point you to a few things in this post, but AWS and others have done a great job documenting how to make Redshift sing for you. You’re buying a BMW here – make sure you know what all those marvelous buttons do!
Here are the top resources you should consider perusing. As you read through this stuff, you’ll note how their guidance dovetails quite nicely with the “top ten”.
The basics:
(These are for you, Ken)
Top 10 Performance Tuning Techniques for Amazon Redshift
Optimizing for Star Schemas and Interleaved Sorting on Amazon Redshift
Periscope Data has done some great blogging on Redshift performance. Troll through their blogs searching for “Redshift”. Here’s a good start:
The Lazy Analyst’s Guide to Amazon Redshift
Advanced:
Long, and awesome. A relatively new 5-part series from AWS:
Amazon Redshift Engineering’s Advanced Table Design Playbook
Test, Over and Over
Whether you like it or not, you must test and monitor. Approaches you can use are documented in a previous post .
When you make a change, check impact immediately. Don’t wait till next week or after you’ve made 5-6 modifications. Test Redshift’s performance but make sure you always gauge your user’s experience executing dashboards. Keep all this data around so you can watch for deltas between upgrades and major shifts in the composition of your data inside Redshift.
What about monitoring, however? We’ve got you covered.
Redshift-monitor
Consider trying redshift-monitor, a fairly new project on github which captures lots of performance data about Tableau and other tools’ interaction with Redshift.

redshift-monitor relies on an AWS Lambda function to connect to your Redshift cluster on a regular basis and capture performance data from system tables.
That data is then stored in an RDS PostgreSQL instance so you can query it with Tableau later. You can extend the list of queries redshift-monitor executes against your cluster if you wish. Doing so will allow you to capture whatever information is of interest to you.
Out of the box, redshift-monitor will give you basic information like query counts and average query execution time, but it will also return much more granular and useful information.
For example, perhaps you’re not sure where to put your sort keys. We’ve got a viz which reports which table / column combinations are being used in WHERE clauses from your queries:
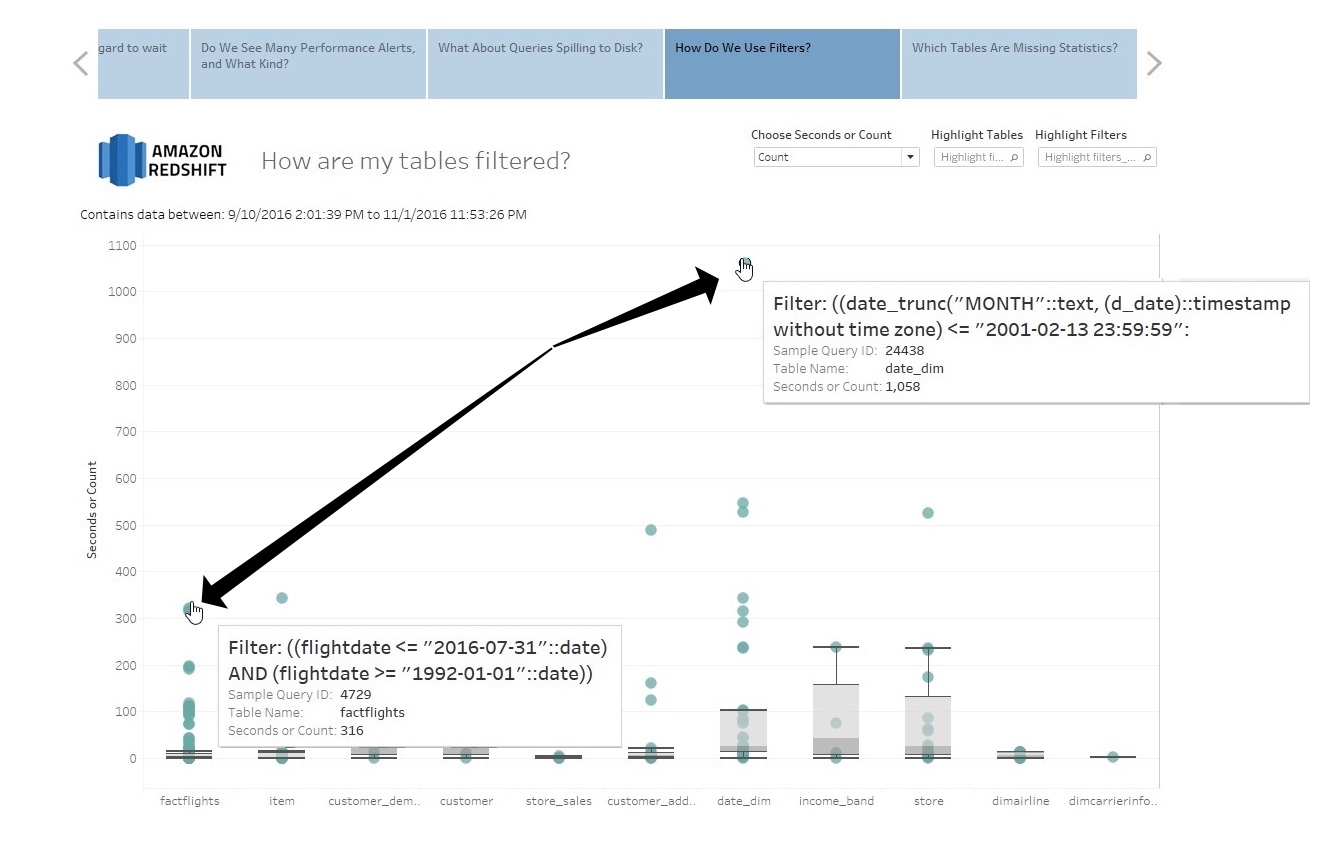
The view above has lots of good stuff. I can see how many times various filters are being executed (or how long the queries they are a part of take to execute).
What is more interesting is I can get insight into the way Tableau is actually being used against Redshift. For example, it’s clear that someone is filtering on date – I probably should put a sort key on that. Fine.
…But look, people are using two different date columns here *:
- d_date in a date_dim dimension table
- flightdate in the factflights fact table
When I see something like this I have to start wondering whether it would be wiser for me to:
- Combine that date dimension with the fact table and potentially get rid of an unnecessary join (Top Ten item #5)
- Modify my Tableau data source in some fashion to remove the field duplication
- Do a little bit of both
Some additional investigation is definitely in order based on the number of times this filter is being used, however.
* This is a contrived example. There are actually two different databases on this cluster, each with “their own” date. I’m just trying to make a point.

Be aware of Redshift Concurrency at all Times
Redshift is not really designed to be a high-concurrency database. Many people overlook this fact when doing their Tableau work, and this oversight could come back to haunt them.
 Whoops! It’s too late! I overlooked this. Can I simply rely on Tableau’s ability to cache data instead? What about using extracts?
Whoops! It’s too late! I overlooked this. Can I simply rely on Tableau’s ability to cache data instead? What about using extracts?
No. Tableau’s caching capabilities are top notch, but they serve a different purpose. You really want to address the root cause of the problem rather than use duct tape to hold everything together. Extracts could be a good solution. We’ll talk about that more later.
A dashboard which is designed first, then built will be awesome on Redshift. When you design, keep concurrency in mind:
- In a single dashboard, execute fewer vizzes
- Don’t use tons of quick filters, or if you do design them so they don’t need to fire a query back at Redshift to populate their values for the user
- Shooting for high query throughput (execution speed) will give you a bit more runway on the concurrency side of the equation
You should also be aware of how Tableau behaves differently vis-a-vis concurrency based on the version of Tableau you’re running:
Nugget: In Tableau v9 and earlier, we were very conservative about executing lots of parallel queries against Redshift. We would only execute 2. Beginning in v10, we will execute as many as 8. This change in behavior could (but often doesn’t) significantly impact your user’s perceived performance. More on this in the final post.
Concurrency Overview
There is MUCH you can read on the subject of concurrency in the AWS docs. What follows is a high-level overview as it pertains to Tableau.
By default, a Redshift cluster launches with a single Workload Management (WLM) queue. It will execute a maximum of 5 concurrent queries. You may modify this value and/or add additional WLM queues that in aggregate can execute a maximum of 50 concurrent queries across the entire cluster.
Nugget: AWS’s current guidance is to fire no more than 15 concurrent queries on a cluster. You may choose to go higher or lower on this value based on the complexity of your queries and how long they take to return rows.
Each WLM queue will be configured to consume a certain amount of your cluster’s RAM and fire a maximum number of concurrent queries. One WLM queue’s RAM can’t be “borrowed” by another. Don’t go overboard creating lots of queues because you’re probably just going to end up wasting resources on queues that don’t stay busy enough to exist in the first place.
You can direct your queries into a query queue by way of User Groups or Query Groups.
A User Group is pretty simple. You create a group in Redshift, you add some Redshift users to it, and then associate that group with a query queue. When a (Redshift) user who is a member of the group executes a query, the query executes in the associated query queue.
Query Groups are more interesting (and useful from a Tableau standpoint). You create a queue in Redshift and associate it with a string…like “Foo”. Then, before you execute your query, you SET its query group:
SET query_group to 'foo'; SELECT * FROM someTable; -- I will execute in the queue associated with the Query Group 'foo'
WLM Queues and Tableau
One trick that some people have used successfully is bucketing their Tableau queries into several different WLM queues. Your goal might be to stick simple, fast-executing queries in one queue and slower, more complex queries in another. Your “fast” queue will allow more queries to execute in parallel and will configured to leverage less RAM. Your “slow” queue will fire fewer concurrent queries and will give them MORE RAM under the assumption they need it.
How do you do this? Create multiple data sources which connect to the same Redshift database. Then, optionally leverage a feature called Initial SQL.
As I mentioned previously, User Groups aren’t very interesting for us. You pretty much would create a data source with a specific embedded Redshift username. All queries executed by that data source will land in a specific queue. Meh.
Query Groups? Much cooler. You can use Initial SQL to fire the SET query_group statement and tell Redshift what it should do. For example, if I’ve associated a WLM queue with the query group “Explore_Data_slow”, I’d leverage that group like so:

But Initial SQL also supports parameterization of what you pass in. For example, I can pass in the name of the workbook ([WorkbookName]) or the name of the Tableau user who is currently logged in ([TableauServerUser])

 This is really useful. For example, let’s say you have a workbook that is critical to closing your quarter out. It must execute in Tableau and Redshift really fast, all the time. For the sake of argument, the workbook is named “QuarterEnd”:
This is really useful. For example, let’s say you have a workbook that is critical to closing your quarter out. It must execute in Tableau and Redshift really fast, all the time. For the sake of argument, the workbook is named “QuarterEnd”:
I could create a query queue which is associated with a query group named “QuarterEnd” and then “pass in” the name of the current workbook to Redshift via Initial SQL. When this specific workbook is executed, all of its queries would be given high priority on the Redshift cluster.

I could also pass in the Tableau Server username and create query groups with matching names. Using this approach, I could manage Redshift resources based on the Tableau user name.
In the screenshot below, I have 3 queues defined. The first is setup to execute only one query at a time, using no more than 10% of the RAM on my cluster.
The second queue will handle the “QuarterEnd” workbook when it is executed. We’ll let 5 queries execute in parallel and each query execution will use no more than 8% of the cluster’s RAM (40% / 5 ).
Everything else goes into the a default queue – we let 8 queries execute in parallel here, using 50% of the cluster’s RAM. Each query in this queue can leverage a maximum of 6.25% of Redshift’s RAM (50% / 8).

Note how 1 + 5 + 8 is less than or equal to 15? That’s not an accident since AWS best practices say no more than 15 concurrent queries running on a cluster.
You can extend the WLM in Tableau approach and attempt to implement it at the dashboard level as well:
- Use a “fast queue” data source for two or three simple worksheets in your dashboard (along with their quick filters)
- Use a “slow queue” data source for a single (or maybe two) complex viz(es) in the same dashboard
- Use cross data source filtering or action filters to re-use the “fast” quick filters and vizzes against the “slow” vizzes
To be completely transparent, this uber-advanced approach is a bit hit-or-miss based on your data and the questions you’re trying to answer in your dashboard. Just try it and see what happens.
Simplify your database schema, simplify your life.
At the highest level, fewer joins is better than more joins.
What this means is that your old third normal form database design probably isn’t going to be very Redshift-friendly. While you’re not generally going to end up with a single flat table, it’s not a completely bad thing to aspire to.
Nugget: Denomalize table schemas wherever you can. Turn your complex 3NF database into a more simple snowflake. Change your snowflake into a star schema. Consider merging some of your dimension tables right back into the fact table.
Nugget: Keep column sizes in your table as narrow (small) as possible. Redshift will reserve RAM for query execution based on the declared width of your columns, regardless of how much data they actually contain. If you get lazy (like me) and don’t think about this, you waste RAM and increase the possibility your queries will to spill to disk. This is bad.
A word on relationships
Relationships are awesome. But with relationships come responsibility. It’s not all fun and games.
Nugget: If you have related tables, you should express said relationships with PRIMARY and FOREIGN KEYs in the database. Tableau will use this information to implement Join Culling . Join culling is good because it simplifies queries by using fewer JOINs and allows Redshift to answer your questions more quickly.
Nugget: If you are a user of Tableau and not the database administrator, you may not be able to make sure PRIMARY and FOREIGN keys are in place. If this is the case, turn on the Assume Referential Integrity option in the Tableau data source. Doing so tells Tableau to “pretend” that the joins expressed in your Tableau data source are backed up with PKs and FKs. Let the wild join culling rumpus start!
Nugget: Make sure the columns you join are tagged with NOT NULL. Tableau is very finicky when it comes to nullability on joined columns. If we see there’s a chance that the fields we use in a JOIN might contain nulls, we actually “sanity check” the data for null values during the JOIN. This will cause Tableau to issue a more-complex-than-necessary query. In some cases, this query will take substantially longer to run than one which doesn’t do null checking.
Select the right Node Type and Count
This topic is a bit outside the expertise of a Tableau guy to discuss at any depth, but it is fairly important nonetheless. Here’s some basic guidance:
Don’t be A meathead
Don’t try to “brute force” your way through slow queries simply by adding additional nodes to your cluster and doing nothing else. You might have some success if your data volumes are low, but you need to do most things right at scale. Brute force by itself won’t get it done for you.
If you want performance use Dense Compute nodes
…the DC1 node type offers the best performance of all the node types. The node type that you choose depends heavily on the amount of data you import into Amazon Redshift, the complexity of the queries and operations that you run in the database.
(Bold is mine, by the way). The questions that Tableau users ask are generally pretty involved. This means complex queries. If you want Redshift to answer complex queries, dense compute nodes are most likely going to be your best solution. Yes, they’re more expensive.
Scale out, then up
Nugget: For any “pool” of Virtual CPUs, EC2 Units and RAM you want to leverage, try to deploy more, smaller machines vs. fewer big machines.
In other words, if I want to run my dense compute cluster with a total of 64 vCPUs, I can get there one of two ways:
- Run 32 dc1.large nodes at 2 vCPU each (32 * 2)
- Run 2 dc1.8xlarge nodes at 32 vCPU each (2 * 32)
I should generally choose the first option. The rule of thumb is that if you can meet your storage requirements with “more, smaller nodes”, do it. Graduate (scale up) to bigger nodes when a bunch of small ones no longer have the storage capacity to host all your data.
Implement Sort Keys, distribution Keys, and leverage compression
Not optional. Really.
This is where you’ll spend a lot of time learning and experimenting. Going deep is beyond the scope of this post since it’s so Redshift centric. That said, I’ve jotted down some thought-objects.
Task: The Advanced Table Design Playbook mentioned earlier is the best guide for this stuff. There are also some more basic tutorials that can walk you through the same material at a higher level. I’d suggest you start with the tutorial to get your feet wet, then move to the design playbook.
Here are are a bunch of stream of consciousness brain-dump mini-nuggets:
- There is no “perfect” combination of sort keys, distribution key and encoding type. You will always end up making some trade-offs. That’s OK
- When in doubt, “just try it” and measure the results
- No, you’re not missing anything. A table can only have a single distribution key
- Remember to put sort keys on the columns which are used as quick filters by your users
- If you have a basic idea of which columns will get filtered (and in analytical workloads, you typically will) use compound sort keys. I haven’t had tons of success using interleaved sort keys
- Investigate putting sort keys AND a distribution key on the fields used in your joins. Do so, and you’ll end up with the fabled merge join, which is very fast
- Don’t forget, the fields referenced in LOD calcs are probably doing some sort of self-join under the covers. Sort appropriately
- If you query “recent data” more often, consider putting your timestamp column as the lead column in a compound sort key
- Let Redshift decide what encoding algo to use when you compress your data. Use ANALYZE COMPRESSION if the size / nature of your data changes significantly.
- Don’t compress the first first column in a compound sort key. You might end up scanning more rows than you have to as a result
- Don’t compress a column if it will act as a “single column sort key” (for the same reasons above)
Aggregate Tables
Summary tables. Love them (who does, really?) or hate them, they can improve performance exponentially at scale.
Not agile, I know.
Pain to take care of, I know.
May confuse your users, sorry.
But they work. When you’re dealing with billions of rows in Redshift, consider creating a few aggregate tables that do things like aggregate your metrics by month or day. You might leverage these with dashboards that you own and must be fast. These could be dashboards that other users won’t ever design and/or modify themselves.
And lets take thing one step further: If you lean on aggregate tables, you may very well end up using multiple data sources to support a single dashboard. If you’re using multiple data sources, maybe you just go ahead and put the aggregate tables in RDS instead of Redshift? Just saying – it could help with concurrency. Not claiming this is a “certified best practice” – just something to think about and experiment with…might as well go Full Monty if you’re so far down the road.
Extracts
At some point during your Redshift journey you will reach this point. I can guarantee it. You will say to yourself, or perhaps out loud:
“Screw this, I’m just going to use extracts”
Redshift-into-extracts can be a great solution. This approach can eliminate entire classes of challenges around concurrency, aggregation, and so on. But you must use extracts with eyes wide open.
Cursor Nugget #1: Assuming you leverage cursors, Redshift resultsets (including extract building and refreshing) are materialized on the Leader node of your cluster. This will slow down the extract process, sometimes significantly. Based on the size and type of nodes in your cluster, there is also a maximum amount of data (between 16GB – 14,000 GB) than can materialized on the leader before an error occurs.
Cursor Nugget #2: When you max out the cursor space and Redshift/Tableau throw an error, you’ve likely just caused anyone else on the system using cursors to fail as well. Go team!
Cursor Nugget #3: If you run out of cursor space but want to stick to your orginal plan come what may, you’ll likely need to invest in a larger node – move from large nodes to 8xlarge nodes, which’ll give you more cursor headroom
<—big nugget.
Q: Well, why don’t I just turn cursors off. Will that work?
A: Maybe. But you’ll need tons of RAM on your system. The exact amount is known as a ‘shit-ton’, which generally is equivalent to much more than you have, no matter how much you happen to be running. It never fails.
So maybe I’m having a little bit of fun at your expense here….But what I’m trying to get as is that you have to be smart about extracts. If you want to download leaf-level data for a 200M row by 200 column dataset, you’re going to have problems. I ran through a series of painful experiments to quantify this, and I’m still pretty sore. Here are some results:

Trying to bring down all 168 columns (or sometimes less) of a 180M row resultset didn’t work. Either I ran out of cursor space on Redshift or RAM on the client (I had 128 GB, BTW). In order to make extracts work, you have to be smart. Any combination of using aggregations and/or rolling up the extract made for a happy life.
Nugget: Aggregate the extract, roll it up. Happiness. Otherwise, suffer.
You can’t aggregate you say? You MUST have all that juicy leaf level data in the extract? I don’t really believe you (use an aggregated extract and a “live” leaf-level data source together). But yes, there’s a way.
Don’t use Redshift. That’s right, I said it. Don’t use Redshift. AWS gives you tons of other great services, too. Leverage them.
How about this?:
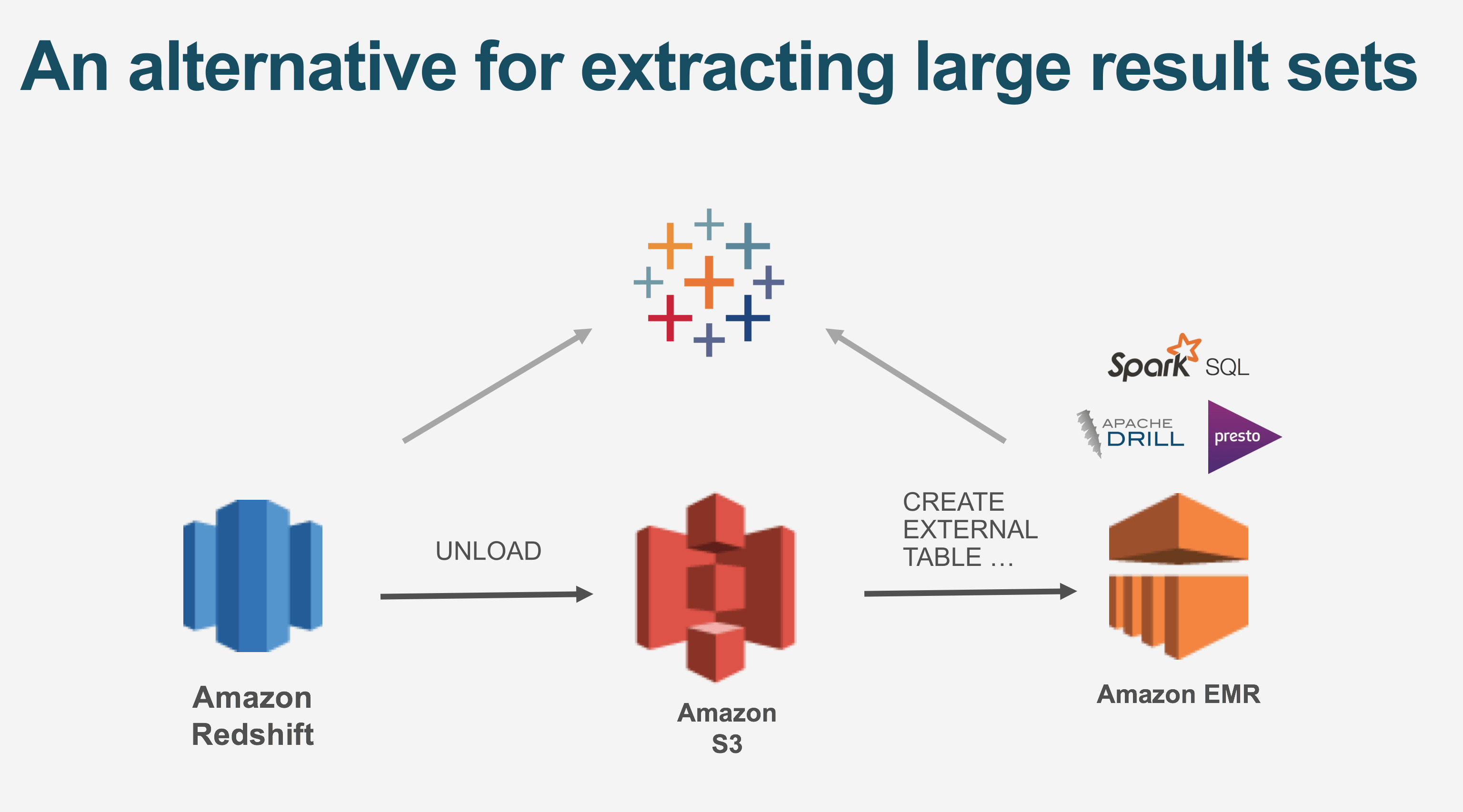
Instead of forcing Redshift to act as an ODS for Tableau, UNLOAD the data into S3 (Redshift is super-fast at this). Then, dynamically spin up an instance of EMR and use your favorite approach to ingest and make the data available. Tableau can extract directly from EMR, and the stand-up / extract / tear-down can be scripted and automated.
…and now AWS has Athena. Assuming Tableau gets a driver for Athena SOON (I’m so passive-aggressive about what I want), you could do this, too:

Learn How to Read a Query Plan
This isn’t especially fun, but at least you’ll be able to amaze and impress your friends. You should be able to read a query plan in order to identify where your queries are having problems. I’m by no stretch an expert, but I’ll give you a little primer below.
Cursors off
Reminder: For you to see Tableau’s query text in the Redshift console, you must turn cursors off. You know how to already.
Here’s the query we’re going to execute against a 10-node dc1.large cluster. The tables are unoptimized except for compression. We’re dealing with ~187M rows, and the query will complete in about 2.5s:

Note the WHERE clause, some GROUPing. We’re JOINing a customer_demographtcs dimension to our fact table. Doing a little bit of aggregation on sss_net_paid, too. Pretty basic stuff.
How To Read
You’ll read a query plan from the bottom up.
Each level consists of an “Operator” (a verb – what action was taken) and 3 metrics:
- Cost: What was the “cost” of this operation? You’ll actually see two numbers here – a beginning cost and an ending cost. Subtract the first from the second
- Rows: Number of rows returned by the action
- Width: The size (in bytes) of each row
Cost is “additive” as you move up through the levels – meaning a parent level generally includes the cost of it’s children.
Cost is also relative – the number itself doesn’t actually mean a whole lot from what I understand. You’re just interested in which operation has the “biggest” number. That’s the expensive bit. Here’s the query plan output from the Redshift console, color coded for your viewing pleasure:

And here’s a walk-through of what happened:
- Scan customer_demographics (cd) table
- Use results to build a Hash table
- Scan store_sales (ss) table
- Use ss results and Hash table to Hash Join against cd – cd is broadcast to nodes
- SUM and GROUP BY with HashAggregate
We start by scanning the customer_demographics table. The cost is about 28K, returns 691K rows of demographic info at 42 bytes per row.
At the same time, we build a hash table to support the JOIN we’re going to need to do later.
Next, we scan the store_sales table. It is substantially larger in terms of rows. Note the higher cost: about 1.9M. Also, note the width of the data is smaller than step 1. We’re playing with INTs now, not heavier CHARs.
We perform a Hash Join. The cost? Some big-ass number. Clearly this is the most expensive thing in town. Joining store_sales to customer_demographics results in about 64M rows with a width of 49 bytes each.
Finally, we SUM and GROUP our data, resulting in an 11 row “answer”.
Console vs. EXPLAIN
If you’re following along really closely, you may notice that something is missing. Take a second and look at the query text above again, then the query plan. Something the query is doing is not expressed in the plan…
Figure it out? When you view the query plan in AWS’s console it’ll be slightly less verbose than if one were to execute the query in a query editor using EXPLAIN.
The Console’s version of the plan isn’t telling us how that WHERE clause was handled. Here’s the same query executed with EXPLAIN in a query editor (note I did this some time later against a different version of the database – so the rest of the plan, costs, and rows ARE a bit different):

For whatever reason, I got a slightly more “complete” view in a query editor. I can see my FILTER operation above, didn’t in the console. Lesson learned. It actually IS useful to know which columns are being filtered (I might want to put a sort key on them).
So what? What do I do now?
While reading a query plan is tons of fun, so what? Why bother? Well, we learned our JOIN is expensive. How can we help support joins? How about adding a sort key on the store_sales.ss_cd_demo_sk column which acts as a foreign key?
Yeah, that would be a good idea.
The result of doing this is a query plan which is essentially identical. However, pre-sorting the store_sales demo actually (I think, anyway) speeds up the GROUP BY. The same query above executed in ~1.5s with a sort key vs. ~2.5s without.
What else could we do? Perhaps a distribution key on the same column in the fact table? Yeah. Let’s try it and see what happens.

- Scan customer_demographics (cd) table
- Scan store_sales (ss) table
- Merge Join the two tables without broadcasting data
- SUM and GROUP BY with HashAggregate
We skipped creating a hash table entirely with this plan. We also do a Merge Join because related columns on both sides of the join have the same distribution and sort key.
Look at the difference in cost on that join! It’s way, way lower. Win! This query completed in slightly under a second.
Lets finish off with a video walk through of the Query tab of the console. Look for the following:
- The Plan and Actual tabs
- The fact that the Actual tab shows you AVG and MAX cost for each operation per node. If you see a big difference, this means you might have data skew (see issue #2) , which is evil
- You can drill into each operation and see the actual cost in seconds.
- By drilling down into each step we can pick up that “missing” FILTER step we couldn’t see earlier
- We can also see the actual columns involved in the “expensive” JOIN – useful for troubleshooting