As always, start at the beginning. If you haven’t read the posts below, you might want to as they will give you the context you’ll need for the brain dump that is this entry.
Overview:
http://tableaulove.tumblr.com/post/117121569355/load-testing-tableau-server-9-with-tabjolt-on-ec2
Results, light load:
http://tableaulove.tumblr.com/post/117201936395/tableau-tabjolt-testing-the-light-load
Today we’re going to talk about the “heavy” load I tested. I’ve had results for weeks and weeks, but I’ve been too busy to write ‘em up and post. They’re actually pretty interesting and a flight home from Seattle to Singapore will give me more than enough time…
Standard disclaimer: My test results may or may not apply to you. In fact, they probably don’t unless your production environment happens to be EC2 C3 instances with Tableau…on 1500 IOPS drives…in the same availability zone I did my testing in…and you’re running the exact same workbooks I did. Get the picture? In essence, don’t get too excited about what you see here one way or the other.
Anyhoo…
The heavy load that I’m driving with TabJolt consists of a bunch of lightweight vizzes that take between .23 – 3.1 seconds each to render on a single 16 core when they are run by themselves with no one else on the system. I added 5 additional “big” dashboards that take between 6.25 and 25.5 seconds to execute in a vacuum.
I ran this workload on the same configurations I did with the light load, ramping from 30 – 170 concurrent users in 10 user increments at 10 minutes each (30 users for 10 minutes, then 40 minutes at 10 minutes, etc. etc.) between each increase in users I bounced Tableau Server. The 30-170 concurrent user test was done with TabJolt’s Interact test – meaning that each test that is executed involves several steps, like:
- Bootstrap (render) the viz
- Get the list of custom views (“Remember Me” variations) that might be associated with the rendered viz
- Filter the Viz
So, every viz which is executed is also “played with” – this doesn’t happen very often in the real world. There is no think time built into this test scenario, which is even a bit more unnatural when doing load testing.
I also ran the “read only” test in which we simply render a viz and go away. I did this for 50, 100, 150, and 200 concurrent users.
full Here are the top level results:

{kind=link}
The trend I saw during the “light test” continued – the 1 x 16 core machine didn’t do very well. In fact, it returned the highest error rate of all the configs I tested.

{kind=link}
Note how the tests per second and sample throughput really fall off around 90 concurrent users and how the response time really spikes @ 130 concurrent users.
Recall also that I’m running disks with 1500 provisioned IOPS, so it is unlikely this drop + spike was caused by some other instance in EC2 “stealing” resources from me.
The 8 core configurations performed in a fairly similar manner, with the v2 configuration (it contained isolated data engines) returning a slightly lower overall error rate.

{kind=link}
The big surprise.
I have to admit, I was sort of surprised by the fact that the clear winner in this test was the 4 machines x 4 core configuration.
While these rigs didn’t complete as many tests as quickly as the other machines at 20-50 concurrent users, they maintained a nice steady state at scale while the other configs slowly dropped off. The error rate generated by the 4 x 4 config was also significantly lower than anything else I tested.

{kind=link}
Now before you go out and start buying up old 4-core processors, lets be clear about a couple things:
- I configured these instances to have good disk throughput. Generally (especially?) when you get a 4-core VM, your virtual machine team is going to give you crap for storage. If that had happened here, I would have had poor results.
- There may have been better 8 core configs. I just didn’t try enough combinations since time is precious.
- I wasn’t running any background jobs while these tests executed. Imagine what would happen if I were to refresh some beefy extracts while TabJolt was doing its work? Bad things, most likely.
- I chose to split 16 cores, which I would consider the minimum for an experiment like this. I wouldn’t generally consider splitting a single 8 core machine into two 4 core boxes. You’ll almost always have a poor experience that way. You want high availability and high performance, you say? Well, you need at least 16 cores. If you can’t swing that much, then you might want to make some design compromises, like sticking all 8 cores into one machine (performance) and relying on good DR processes to minimize downtime (vs. trying to implement HA).
Because we render the “heavy” 6 – 25 second vizzes (literally) hundreds of times each, our average response time is going to go up vs. the “light” test. Note how the 4 x 4 v1 configuration has a higher overall average response time:

{kind=link}
Since the 8 core configs are able to pump vizzes out faster at between 20-50 concurrent users, they manage to respond between 2-3 seconds faster on average across the whole workload…However this advantage would have likely disappeared if I continued to pound away with additional users where the 4 x 4 has the advantage.
Using the “Metric Deep Dive” dashboard, we can look at this behavior a little bit more closely:
Using 9’s fancy new Instant Analytics, look what happens when we’re comparing metrics for 20-40 concurrent users…the 2 x 8 Core config wins – more samples at a lower response time and a higher TPS:

{kind=link}
Now, let’s take a look at what happens when we really start driving heavy load. The tables are turned – the 4 x 4 is a clear winner:

{kind=link}
And we see the same thing in the “Compare Different Configurations” viz…2 x 8 about 12% more TPS when running between 20-40 concurrent users…
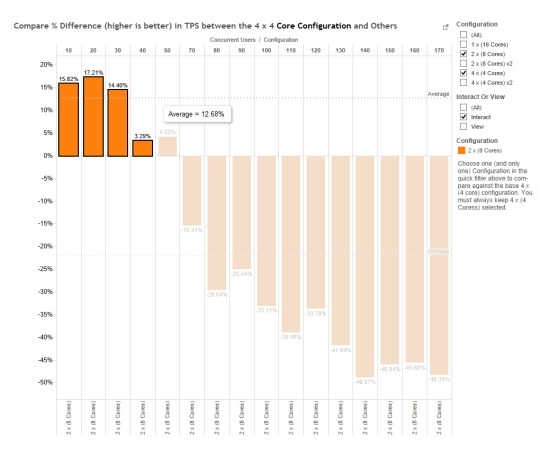
{kind=link}
….but 4 x 4 nearly 34% more TPS when we run 50-170 concurrent for an overall ~22% win.

{kind=link}

{kind=link}
Let’s finish off with “Waiting is a Terrible Thing”. Note that our 4 x 4 shows the lowest increase in average wait time as we scale up 10 users at a time.

{kind=link}
So that’s it campers. Another example of how TabJolt is awesome. When you have a question, don’t guess – just install TabJolt and get an answer for yourself. It’s fast, free, and dare I say…fun?
The posts in this series have been nothing short of amazing in helping me use TabJolt to test different configurations for a client I’m working with. Just out of curiosity, what’s the reason you chose 10 minutes for your test duration? Is there much difference in the results compared to 5 min tests?
I’d also be interested to know if you tested a sample of known vizzes or if you tested everything on the server in your tests. Would there be a benefit in doing the latter?
Thanks
Glad they’ve been useful!
10 minutes is sort of arbitrary. My thinking: Based on # of vUsers, I know that I’ll often want to ignore the first 1-2 minutes of the test. I also know that we begin to ramp down the number of users in play at the end of a test, so I ignore the last minute or so, too…10 minutes gives me 6-8 minutes of “steady state”.
There are also some behaviors that you won’t see unless you run tests longer: VizQLs recycling, etc. Sometimes that stuff is interesting.