I SWORE I would take the rest of my vacation off from blogging.
And then I changed my mind.
A couple weeks ago, AWS released a new feature for EBS Disks: Elastic Volumes. At the highest level, this improvment allows you to change your volume configuration and size dynamically. You read that right – you don’t need to shut down your ec2 instance (and therefore Tableau Server running on ec2) to change how your disk functions.
“That’s pretty damn cool”, I thought to myself as I read the blog entry above on my phone. There are numerous scenarios where this capability could come in handy, including:
- Changing Tableau’s disk type from SSD gp2 (general purpose) to PIOPS (provisonioned iops) during periods of very high usage and periods where disk throttling could occur
- Using combinations of CloudWatch and Lambda functions to automagically increase disk size and alert the administrator rather than let a full disk bring Tableau Server down
However, since I was on an island off the coast of Cambodia and was lucky to get an EDGE connection, there wasn’t much I could do about it.
Now that I have my fine, fine 4G in Indonesia. I can.
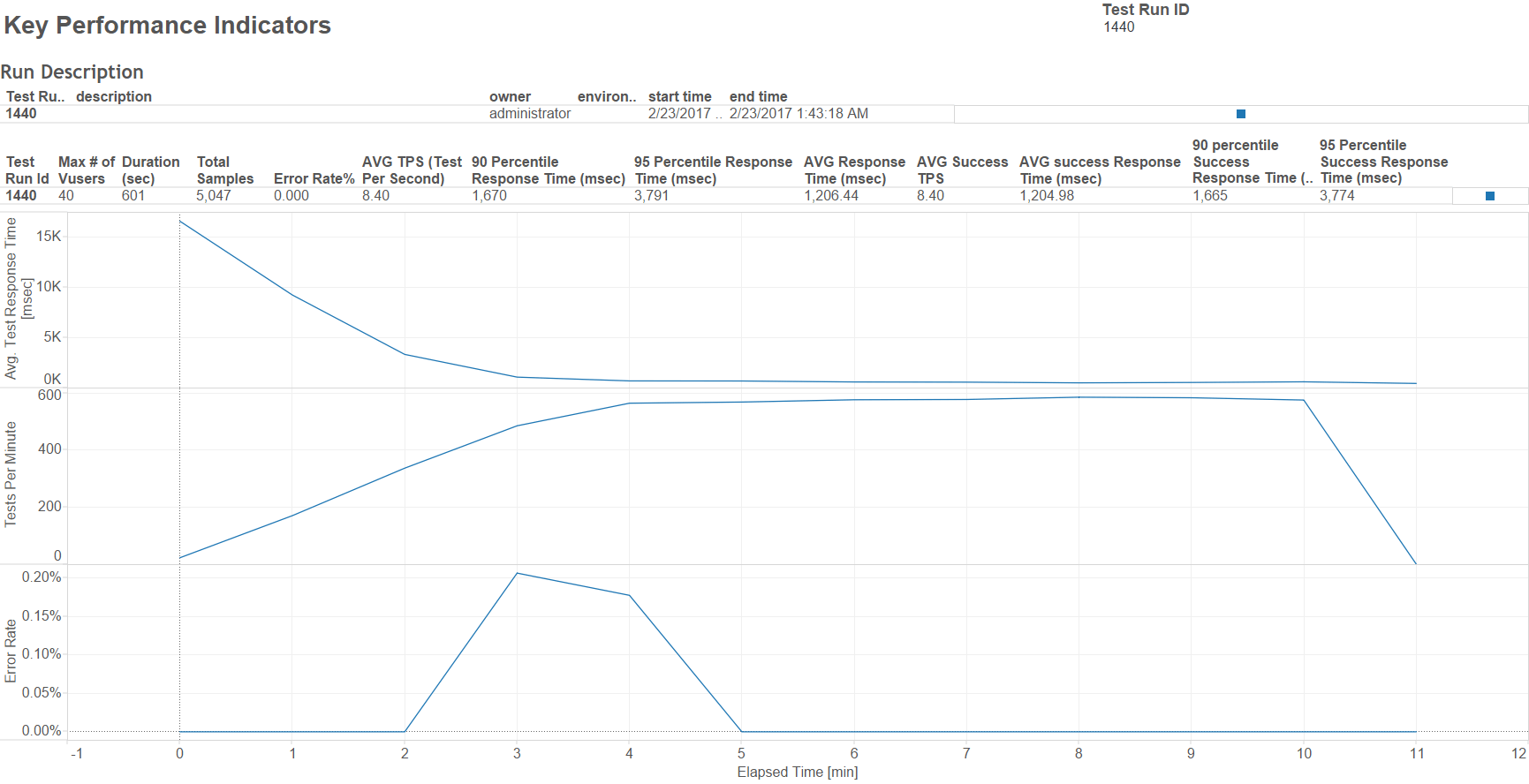
So, I executed an hour-long TabJolt test against Tableau Server running on an r4.4xlarge. TabJolt “pretended” to be 40 virtual users, and I went with 60% “View”, 40% “View and Interact” in terms of how TabJolt actually rendered reports.
(Aside: I can do work from the porch of my villa in Ubud. That’s what’s awesome about the cloud)

I gave the Server 10 minutes to settle in, then I changed the disk type from SSD GP2 to PIOPS. I dialed in 2000 IOPS, which should be more than enough for Tableau:

After hitting Modify, I sort of expected Tableau Server’s performance to take a “hit” as AWS did “disk stuff”.
Much to my suprise, this didn’t happen. As you can see below in my test results there is no meaningful variation in TPS or Average Response Time during the modification process. It’s almost perfect.

Turns out, AWS documentation says the following (bold is mine):
While the volume is in the
optimizingstate, your volume performance will be in between the source and target configuration specifications. Transitional volume performance will be no less than the source volume performance. If you are downgrading IOPS, transitional volume performance will be no less than the target volume performance.
So I’m just postitively overjoyed right now.
FYI, the docs say that the length of time it’ll take to apply the change to your volume “depends”. It gives an example of a 1 TB volume needing 6 hours. For me (on an 100 GB volume) , it took ~25 minutes to go from this:

To this:

And frankly if it doesn’t impact Tableau Server’s performance I kind of don’t care how long it takes.
The last little experiment I want to run is to see what happens when I first increase the disk (to maybe 110 GB, switching it back to GP2 along the way) and then actually expand it in Windows while Server is rendering vizzes. I’ve never tried doing this before because it wasn’t even a possibility.
And an FYI, I just TRIED to do the re-configuration, and AWS yelled at me: It looks like you can only reconfigure disks every 6 hours?


So don’t go crazy.
I’ll try it later, but this is awesome stuff.
EDIT: Later.
It took about 57 minutes for me to re-configure the volume “back” to gp2. Along the way, I increase volume size by 5 GB to 105 GB, which is what I suspect made it take longer.
After the process was complete, I ran a 10 minute TabJolt test using the same parameters I did previously. at 5:30 into the test, I extended 100 GB D: volume to 105 GB using the Disk Management Tools in Windows. It happened really fast, and and as you can see below, it made NO difference to Tableau: between minutes 5 and 6 we’re as clean as a whistle: