
Setting the Stage
In past entries, we’ve:
- Framed the Tableau-Redshift relationship
- Discussed how to measure performance
- Laid out things you should and shouldn’t do vis-à-vis performance
In this final post I’ll attempt to put everything together by applying what we’ve learned to a real-world scenario.
The goal is to (within reason) see how Redshift behaves in the field when we take the training wheels off and “do our worst” with Tableau.
I used TabJolt to exercise 10+ different vizzes published to Tableau Server. Each viz connects to the same instance of Redshift. A single virtual user executed these vizzes for about an hour, making sure to bypass Tableau’s cache.
The goal was to force Redshift to work hard, so we don’t want Tableau’s cache getting in the way and making Redshift’s life easy. The perceived performance results you’ll see are therefore “worst case” because we always wait on an answer from Redshift before the user gets a result.
To make things interesting, I used 5 copies of the same database and optimized each differently (sort keys, distribution keys & styles, variations in database schema) so we could see the outcome from the perspective of a Tableau user. I also tested these databases with different amounts of data. More on that later.
I leveraged clusters running different instance types and counts:
2, 5, 10, 32 Dense Compute (dc1.large) nodes
- 2 vCPU / 7 ECU each
- 15 GB RAM each
- 160 GB SSD storage each
2 Dense Compute (dc1.8xlarge) nodes
- 32 vCPU / 104 ECU each
- 244 GB RAM each
- 56 TB SSD storage each
At times, I’d randomly have another user executing the same vizzes on Tableau to create concurrency issues. I then experimented with WLM settings to increase the number of concurrent queries the cluster could execute.
After running baseline tests, I moved into a “tuning” stage and used our Tableau-Redshift “rules of thumb” in order to INCREASE performance.
My tuning goal was NOT to end up with “the singular, uber-fast viz”. Since this is all make-believe anyway, that seemed like a waste of time to me. In fact, several times I left things in a “good enough for the moment” state and moved on. My real focus is to demonstrate the type of things you can do to improve performance: you can take these ideas and then vary / extend them as you see fit.
When all was said and done, I ran upwards of sixty hour-plus tests and managed to generate some pretty useful data.
Let’s get started.
The Vizzes
I created a workload with a mix of vizzes which fall between “simple” and “complex”. The simple vizzes generally fire one or two queries and do basic filtering. As you’d expect, the big, ugly dashboards contain many worksheets and quick filters (don’t do this) and as a result fire MANY queries at Redshift at the same time:

The Data
Schema
I generated three sets of TPC-DS data and leveraged a subset of the TPC-DS schema. Essentially, I used the store_sales fact table and supporting dimensions, then ignored catalog & web sales and returns.
The datasets I generated included some foreign key values in my fact table that didn’t exist in the associated dimension tables. I don’t know whether the folks at TPC did this on purposes OR if I simply made a mistake, but I went with it – having dirty data is sometimes a fact of life.
As a result, I used lots of LEFT JOINS in my Tableau data source, which probably prevented most join culling from occuring (recall that join culling is good for performance). Here is what my data source looked like in Tableau:

Data Volume
I mentioned three sets of data – pretty much these represent small, medium, and larger datasets. Here are the approximate number of rows in each of the three data sets:

Since I hate waiting, I tended to use the 180M row fact table dataset to “learn with”. I then would swap over to the 390M or 3B row dataset to confirm that behavior was more or less the same and make additional adjustments if necessary.
Table Design
Finally, here are the five (similar, but different) database designs I went with. At the highest level, each database uses the exact same tables, columns, and referential integrity constraints as defined by TPC-DS.
They differ when it comes to the “Redshift stuff” around sort keys, dist styles/keys, etc. . I created each one pretty much at random using a “best guess” approach. I didn’t think too hard since I figured I’d need to optimize later anyway based on test results…and boy, did I ever.
 Lesson learned: It won’t be perfect at first, don’t waste too much time attempting to make it that way up front. Instead, iterate.
Lesson learned: It won’t be perfect at first, don’t waste too much time attempting to make it that way up front. Instead, iterate.

The key thing to note here is database v1 is essentially unoptimized. Redshift will automatically use an EVEN distribution style if none is specified, and I didn’t bother putting in a sort key. The other designs represent me trying various other sort key and distribution key/style combinations on the fact and dimension tables.
You may notice that database v3 is sort of highlighted in the table above – that’s because it happened to be the most efficient “out of the box”.
Baseline Results
I grabbed performance data using the techniques I described here. I generally went with bump charts to help highlight performance changes over time as I experimented with the sort keys, dist keys, and schemas of each of the five test databases.
The bump chart isn’t really appropriate for communicating initial/baseline results since all this stuff pretty much occurred at the same point in time, but whatever. I’m lazy sometimes.
There were also a few instances where I ran a test incorrectly, realized it afterwards, and decided NOT to re-run it. I started getting sick of testing after a while, so you’ll have to forgive me.
Query Execution
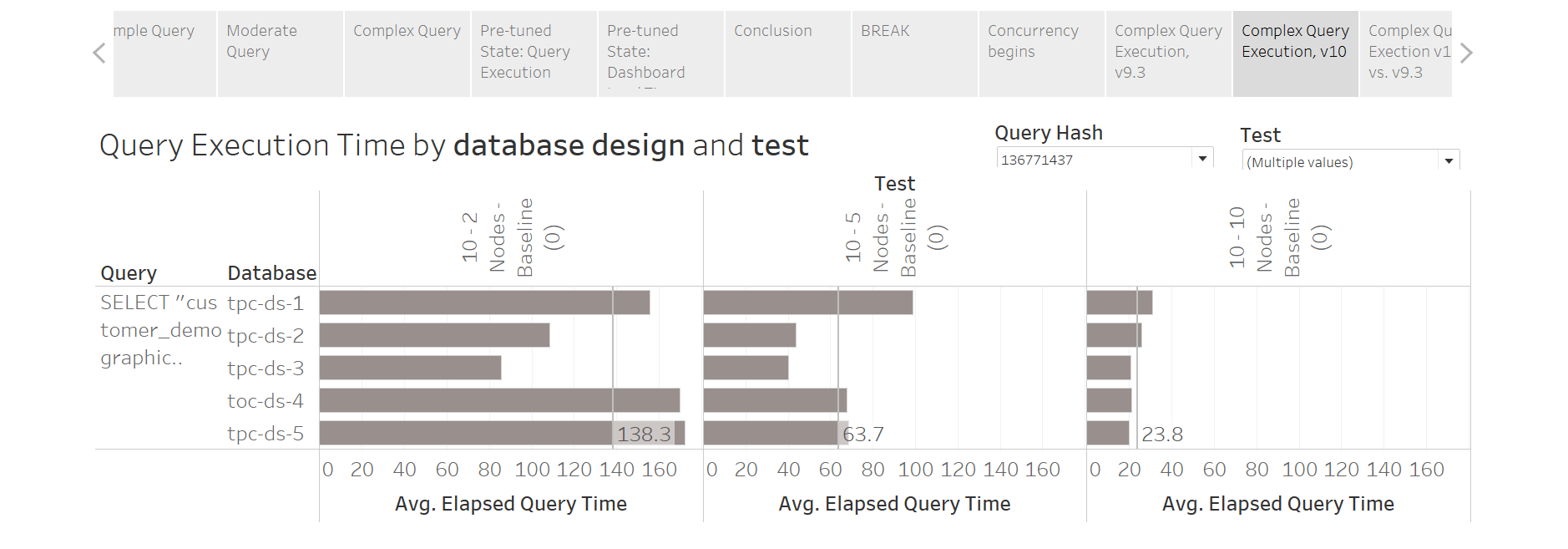
Below you’ll see results of testing Tableau Server 9.x and 10.X against a Redshift cluster running 2, 5, and 10 dc1.xlarge nodes on top of 180M rows. I’m ranking the Average Elapsed Query Execution Time on Redshift for ALL queries fired against each of the five databases by Tableau Server.
Each one of those marks aggregates both “fast” and “slow” queries executed against the database during a specific test. This specific bump chart was a good way to get a general feel for where to look for trouble, but was not great for doing real troubleshooting. It isn’t granular enough.
I found myself creating additional small-multiple bump charts at the level of the dashboard, viz and even at the level of each query behind my vizzes to do “real” investigation and deep comparison
Anyway, data:

I used good old MSPaint to draw a few rectangles around the 2, 5, and 10 node clusters. Each group contains a v9.x and v10.x test for the node count in question. That red arrow points to a test that I messed up. I forgot to force a refresh one of the 10-ish vizzes being executed, and this minor boo-boo was all it took to put this specific test “to the top”. It’s wrong.
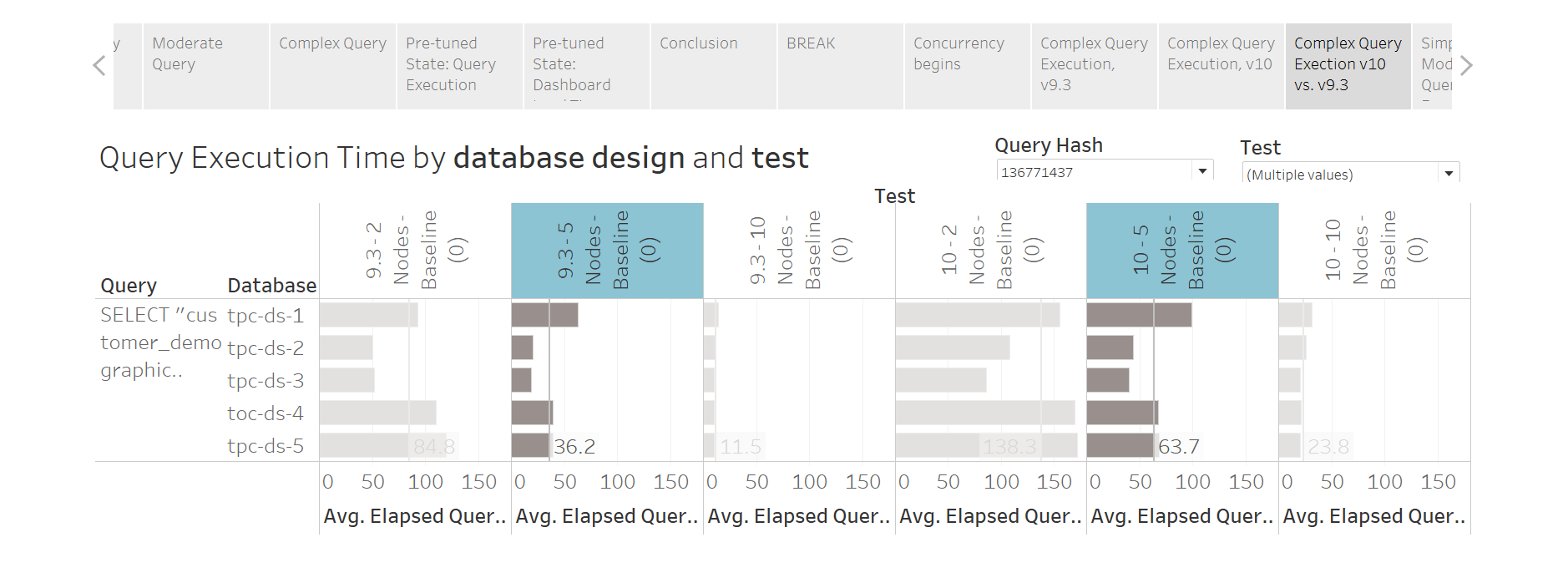
As I mentioned earlier, database design #3 (light blue) is the clear winner. It is ranked #1 or #2 fastest in every baseline test. Database design #1 (orange) is unoptimized and is the worst performer.
Here’s the same bump chart, but with Average Elapsed Query Execution Time as the label for each mark. You can clearly see how these suckers get faster when you throw more horsepower at ‘em.
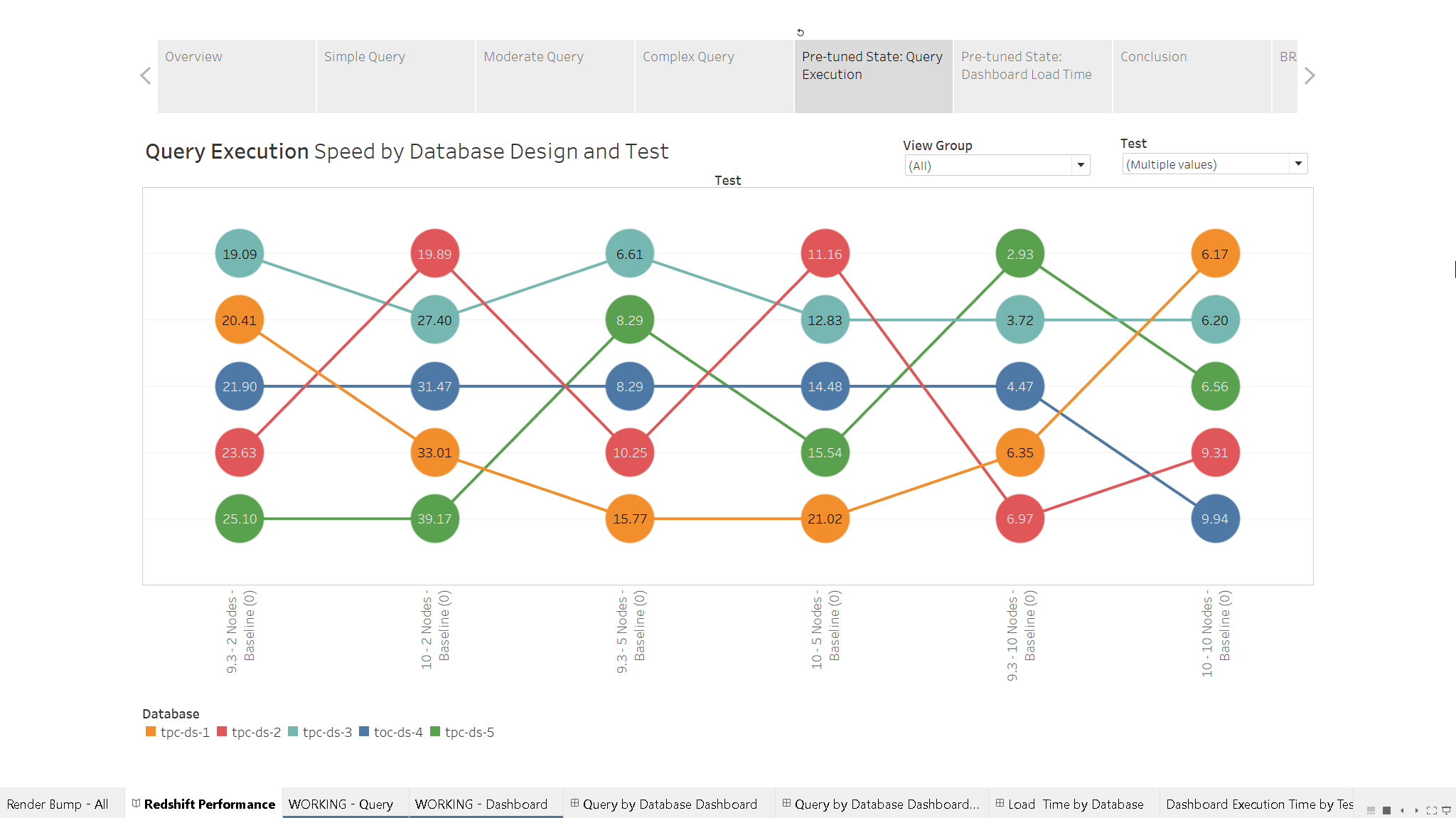
Something else that jumps out at me is the uneven performance between Tableau 9.x and 10.x against Database #2. Note how performance is always quite good with v10 and bad with 9.x? Results for Database #2 are much, much better than any other design on the 2-node test. It looks fishy to me, frankly. If I had all the time in the world, I’d probably re-run these tests to make sure I didn’t make an error of some sort. But I didn’t.
If you want to see what this looks like at a Dashboard level, here you go. I’m not putting the image on the page as it’s way too big.
Perceived Performance
I’ve talked a bunch about “perceived performance” – the actual load time the user experiences in Tableau Server based on what Redshift does for us. What does that look like? In this case, it’s the same:
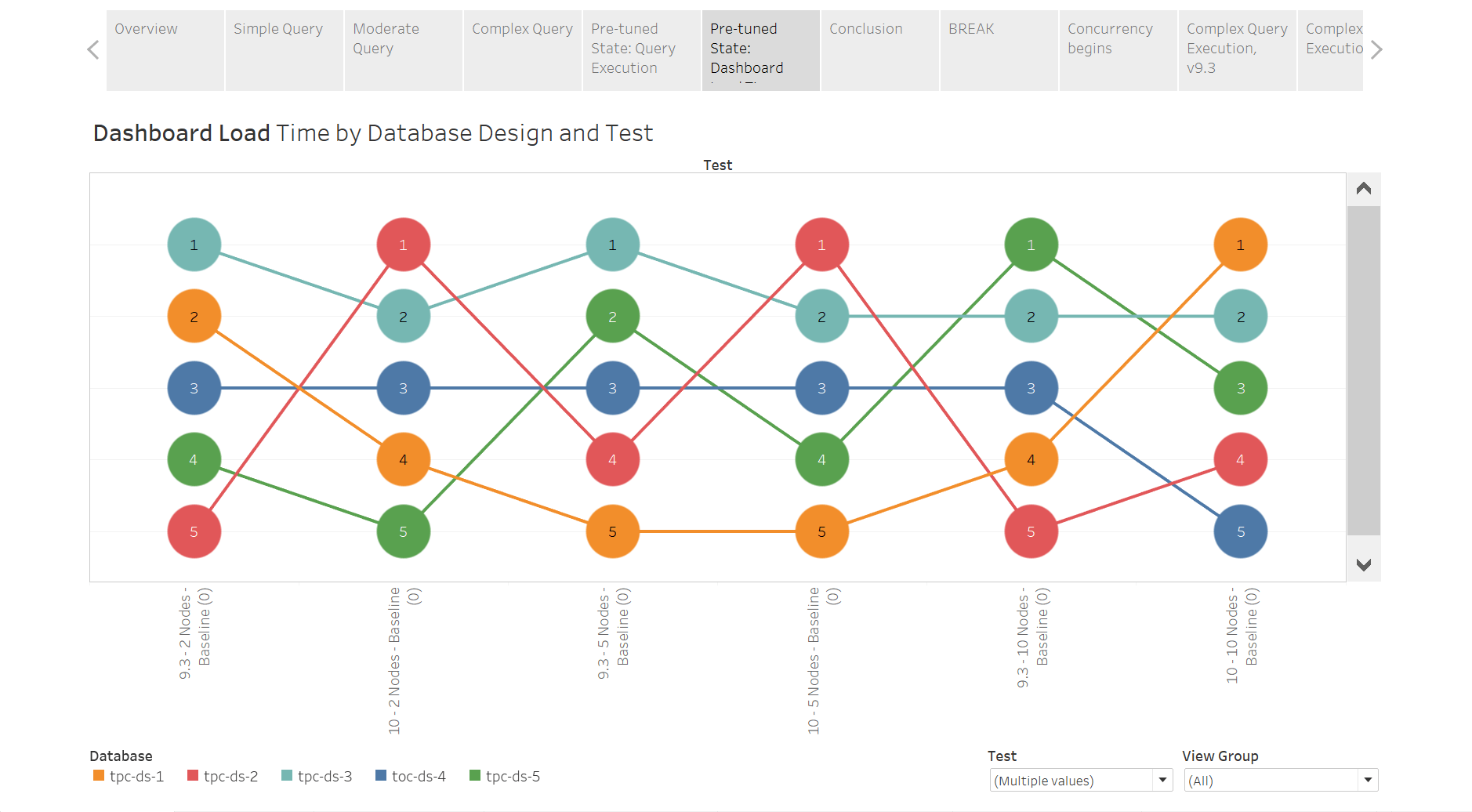
Perceived performance is (largely) driven by query execution time. This should not be news to you. Here’s the same bump chart with Average Load Time being used as the mark label. Each mark represents the average load time for ALL the vizzes tested (some of which render fast, some of which are reallllly slow)
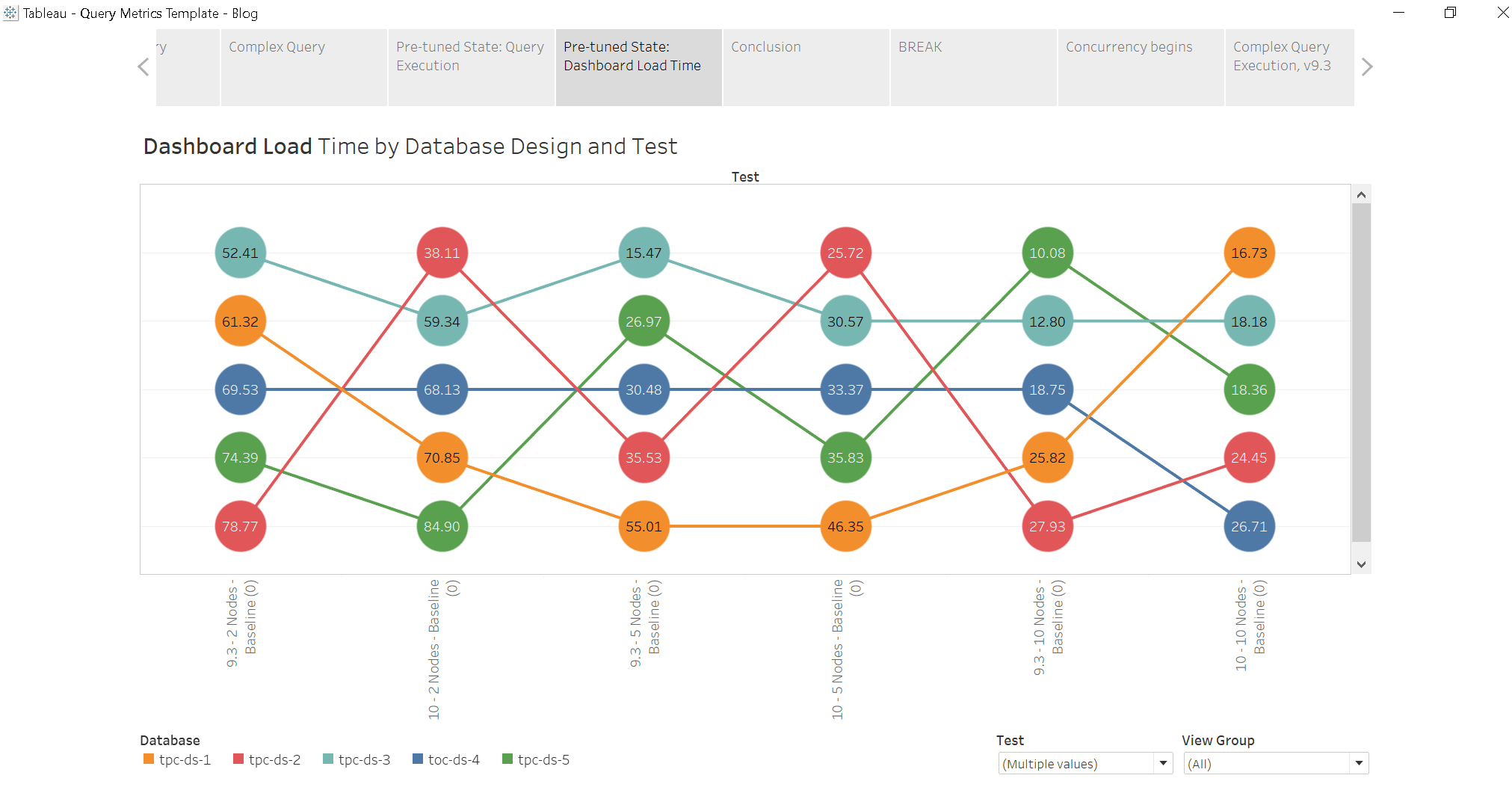
Impact of Concurrency on Baseline Results
We already know that you can run into concurrency issues on Redshift. We’re about to measure that impact.
Multiple Queries
Recall that Tableau v9 will (by default) fire a maximum of two concurrent queries at Redshift. V10 will execute up to eight. A “virgin” Redshift cluster will have a single WLM queue with its initial default concurrency value set to five. Therefore, we could get up to five concurrent queries executing on Redshift (based on v10’s “up to eight” behavior).
Below, we’re looking at query execution time (in seconds) for one of the most expensive queries fired by my ugliest dashboard. It’s a very complex query which joins 6-7 tables, leverages a subquery, and utilizes a nasty WHERE clause which contains CONVERT functions along with IN. We see results for each of the five 180M row databases across 2, 5, and 10 nodes for Tableau v9.x. This specific query is being fired in parallel with other queries which support the same dashboard.
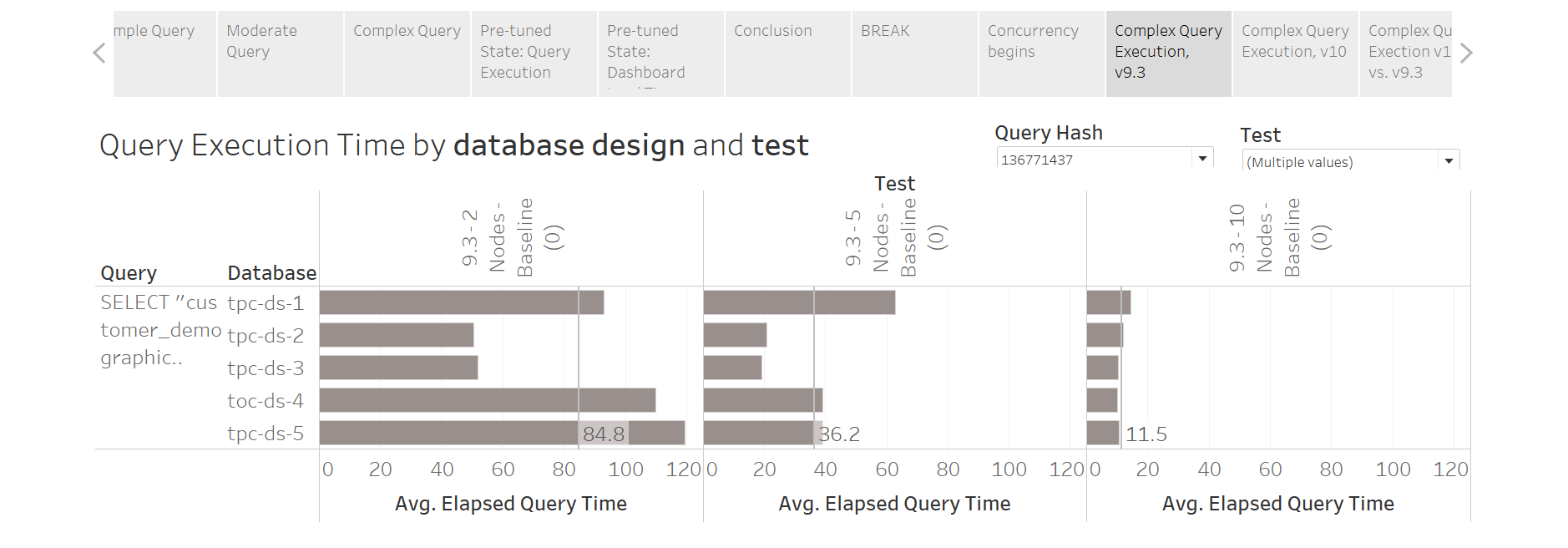
(While completely irrelevant, this sucker actually performs BETTER on the unoptimized DB#1 than it does on the not-very-well optimized databases #4 and #5).
Now, v10. Hold on to your hats:
Now, both together for clarity:
If you just thought to yourself, “Holy crap!”, you win the prize. You’re seeing proof positive that firing “many” meaty queries at the same time can make them all slow down. FYI, the same behavior generally doesn’t occur with “light” queries from what I’ve seen. Here’s one of the more basic queries fired:
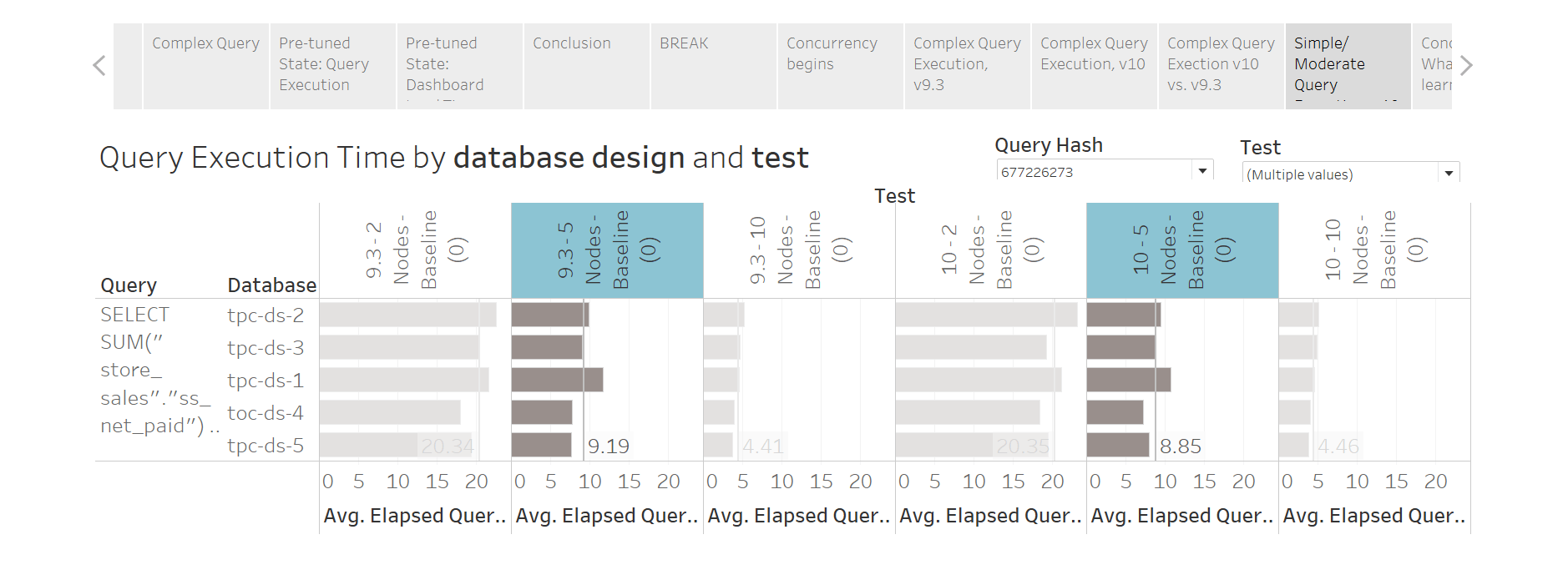
Note there’s very little difference here between v9’s “two concurrent queries” and v10’s “eight (but really five)”.
So, right now you’re probably in tears. Never fear. We’ve only been looking at query execution time…let’s explore perceived performance for the dashboards which executes the (big,ugly) and (small, lightweight) queries:

Perceived performance is pretty close….
It seems that firing a big batch of “relatively slower queries” vs. several smaller batches of “relatively faster” queries is generally going to result in about the same performance. Your mileage may vary, of course.
And remember, you’re also looking at worst case performance because I’m forcing viz execution to ignore the Tableau Server cache altogether.
Multiple Queries Executed by Multiple Users
To make the exploration of concurrency more interesting, I ran several tests which leveraged a second ‘sleeper’ virtual user.
The sleeper would wake up once every three minutes and execute a dashboard randomly. Then, the sleeper would take a nap again.
In the best case scenario, “sleeper” might execute a viz which happened to only fire one query. On the other end of the spectrum, “sleeper” might run a “big ugly” dashboard, which depends on 8-9 queries. Let’s watch perceived performance on a 5 node cluster using ONLY a single user. I’m focusing on results for a specific, “big ugly” dashboard because it is worst case scenario and shows more variance:
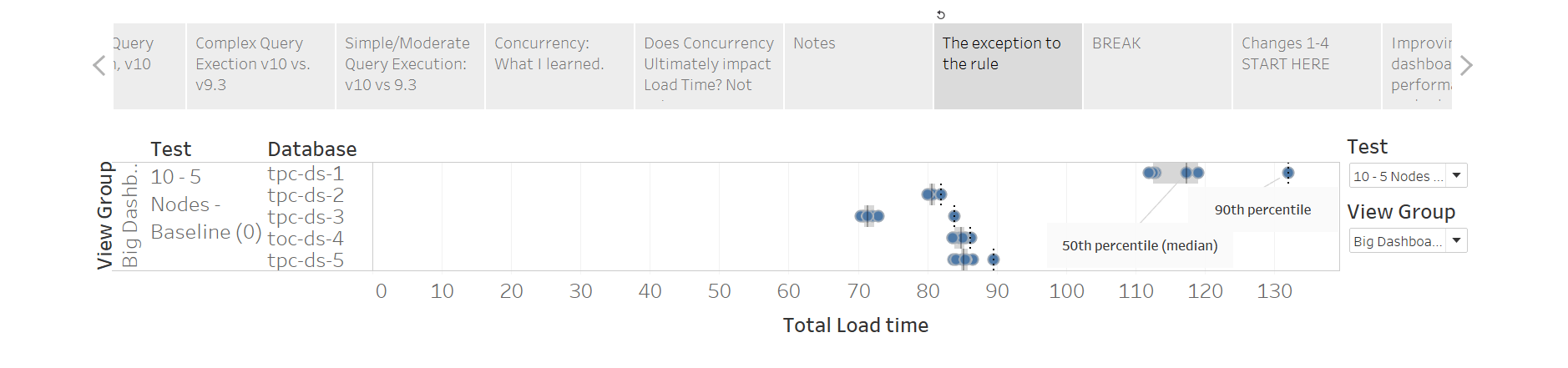
Note that there is little variation between the render times in a single database. FYI, the solid line you see for each row represents the median load time (50th percentile). The dotted line represents the 90th percentile. I use 50/90 as a simplistic way of understanding what “average” and “bad” performance looks like to my users.
Next, we turn the sleeper “on”:
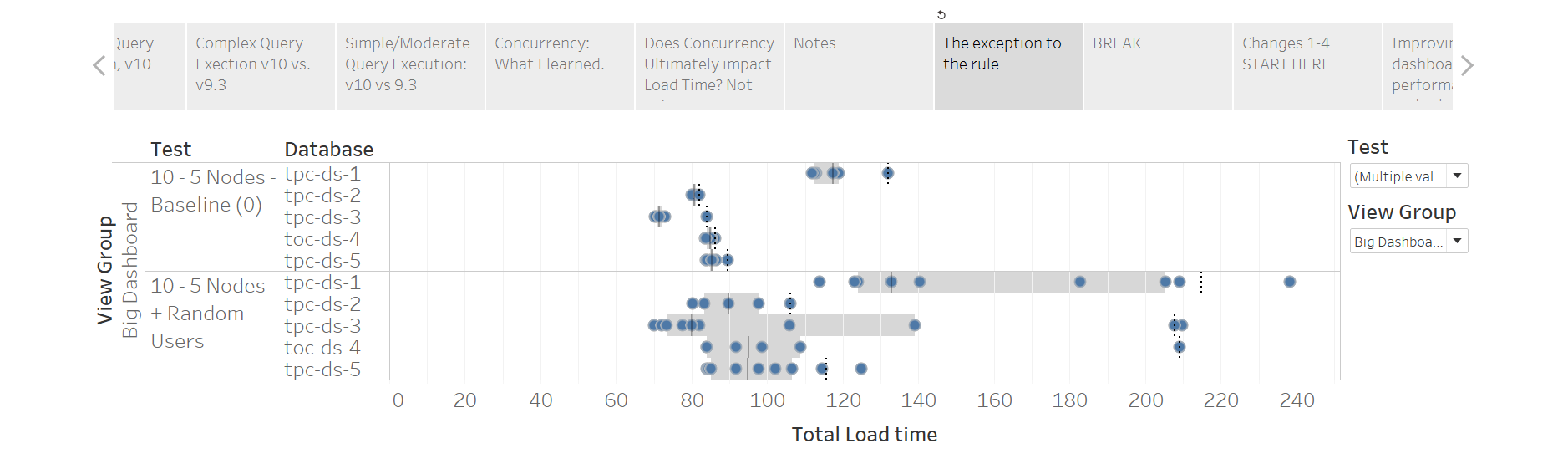
Zoinks! Tons of variance. The difference between “average” (median) and “bad” (90th percentile) performance is huge now…and that’s understandable: Redshift can only run 5 queries in parallel right now, and two dashboards worth of queries can easily eat that number up and cause Redshift to queue.
Finally, lets change the maximum concurrency of our single WLM queue from 5 to 15. As you recall, 15 is the maximum AWS normally recommends:

Performance still isn’t great but you can see some improvement. The gap between 50th and 90th percentile narrows for database designs one, three, four, and five. I have NO idea what’s going on in database #3 – results get WORSE there, not better. Weird.
If do the same thing on a ten-node cluster, we see a different story:

With ten nodes, Redshift can service queries fast enough that the additional work created by “sleeper” doesn’t really impact the overall experience too much. Median load time stays about the same no matter what we do.
Let’s make some changes!
So far, you’ve only seen the “out of the box”, baseline state. Now we’re going to start doing some very basic performance tuning.
Since database #1 (the slow one) is essentially a blank slate, we’ll focus efforts there so you can actually see the difference in performance when we make a change. I’m also going to focus on the slowest dashboard, since users will clearly be screaming bloody murder about it.
So… Our big ugly dashboard takes ~117s to render against Database 1 on a five node cluster:

Step 1
The very first thing we’ll do is add sort keys to the main fact table and a few of the most important dimension tables. I’m generally just going to sort by fields which make up the primary key of the dimension table. The fact table sorts by the item being sold, and the date it is sold on:

While the dashboard being driven by database #1 still is the “slowest”, that single change shaved ~27 seconds of the dashboard load time (117s to 91s). Not a bad day’s work.
Step 2
I added a distribution key to the fact table. I chose to partition by the “item”(item_id – the thing being sold) column as there were a large number of items and the count of each item sold was pretty even. No skew!
I also modified the sort key on the customer demographics dimension table so that the fields my SELECT statements generally went after were included in a composite sort key.
Finally, I used the dist style of ALL for all other dimensions in an attempt to cut down on cross-node chatter.
You can see execution time dropped from 91.6 seconds to ~76 seconds. Another nice win.
Step 3: Whoops!
Everything I’ve read told me that using interleaved sort keys in an analytical database might not be the best idea.
But I don’t believe anything I read on the internet. (Fake news, and all)
So, I swapped out my single-and-multi-column (compound) sort keys for multi-column interleaved sort keys. I put 2-3 column interleaved keys on most of my dimension tables based on the fields leveraged in JOINs. My fact table got a 5-column interleaved sort key which referenced all of the dimension keys used the most often in the JOIN clauses my created by Tableau.
Like I said, whoops! I lost 13 seconds on that experiment. Lesson learned. Sometimes you can believe the internet.
Step 4:
I rolled back the sort key changes.
Then, I fiddled with the sort key of my fact table, reversing it from (ss_item_sk, ss_sold_date_sk) to (ss_sold_date_sk, ss_item_sk): Many of the vizzes in this dashboard are time series, so making time the lead column in the compund key make sense.
Putting the sales date out in front appears to have been a winner because I shave another 12 seconds off my previous best. We’re now down to 65 seconds.
…And you get the ideA
Make a change, and test, make a change, and test.
In step 5, I tried a different distribution key on the fact table. I noticed that one of the slowest queries being executed by Tableau included a JOIN against the stores table. I hoped that re-organizing the data and partitioning it by store instead of item might improve things. It did! but it made everything else slower…so net:net, it wasn’t a win.
Remember that your dashoboard is a “system”. Tuning the hell out of one query won’t do you a bit of good if your “fixes” negatively impact other queries. Sometimes “good enough” is as good as you’ll get.
At this point, we’ve improved “from a dead start” perceived performance of our dashboard by ~90% by going after low hanging fruit in Redshift. There are likely more gains to be had, but I got the feeling I was entering the land of diminishing returns, so I stopped tinkering with Redshift.
Basic Dashboard Modification
Instead, let’s focus on Tableau. Below you’ll find the dashboard we just did a bunch of testing with. It its current state, it will execute 7 queries against Redshift. In the screencap below, it is hitting a 2-node Redshift cluster with a database size of 180M rows. Against this undersized cluster, Redshift must perform > 330 seconds of query execution. That’s a hell of a long time.

We’ll apply some basic techniques here – most of them are not even Redshift-related. They come from Alan’s Designing Efficient Workbooks whitepaper:
- Change the (range) date filter to a relative data filter – this saves us from having to fire a query at Redshift to establish the start/end date we show the user
- Date is one of the sort keys on our fact table. This means that filtering down to a smaller date range will allow Redshift to do far less scanning to get an answer to our question. So, we’ll change the range filter so that it returns “only” 12 months of data instead of 31
- We have too many categories being displayed in the sparkline-ish viz. We’ll add a new filter and return 4 categories by default instead of 10.
Here’s what we get as a result:
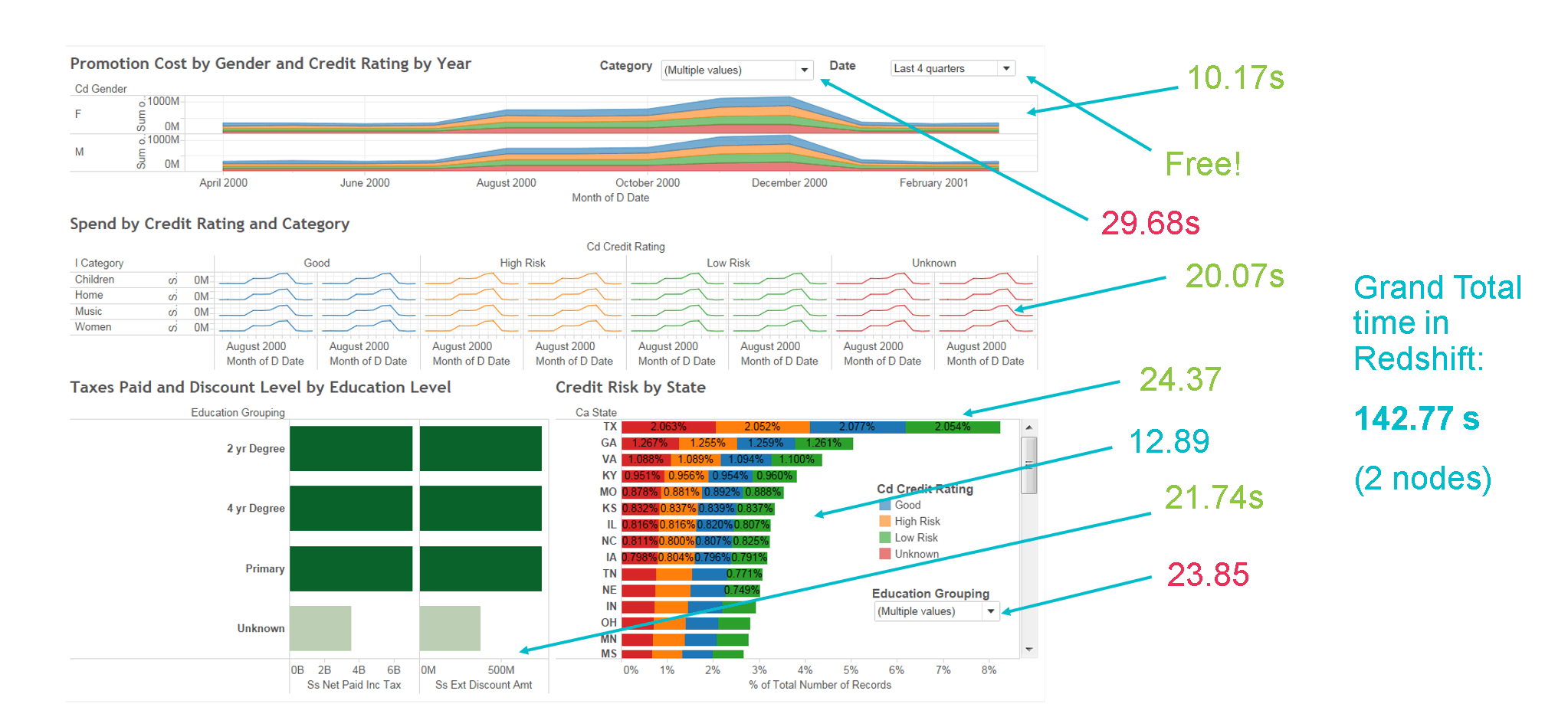
Redshift spent less than half the time it did previously to get us data. Nice.
Granted, doing this experiment on a 2-node cluster overstates said improvement since Redshift is undersized to begin with. But still.
Note: I really should have done this work on a 5-node cluster, too: I don’t know what I was thinking. I also should have kept better notes because the ~22 second increase we see in perceived performance seems low to me:

As I recall, I did a second round of tweaking (included in the 142s result) that were not included in the “shouldn’t it be faster?” 129.7s dashboard load time number.
But since I did this work months and months ago and I did poor job of recording exactly what I did and when, I’m just not sure. Sorry. I failed my science lab with this oversight.
Database and Workbook Renovation
Thus far, you’ve seen how you can substantially improve performance with what I’d consider “tweaks”. Next, we’ll make wholesales changes to the database schema and dashboard. Here’s what I did:
- In Database 5, I merged the most often used dimension value columns directly into the fact table. I did this with most, but not all dimension tables.
- I updated the Tableau data source connecting to Database 5 to “pick up” my new fields
- I used those “new fields” in the dashboard instead of the old ones
- I removed joins in the data source to “old” dimension tables so that they couldn’t be included in SELECT statements created by Tableau <— Important!
Note that the workbook I modified is what you see in Figure 20, NOT the “improved dashboard” in Figure 21.
To show a “continuum of improvement” I should have done the latter. I also didn’t apply ANY of the sort key / distribution key learnings to database 5. DB5 is still running with the “out of the box” schema I arbitrarily created for it when I ran my baseline tests. Net-net, there’s still lots of room for improvement here.
Nevertheless, it’s clear that Database 5 / Big Ugly Dashboard 5 leaps ahead of the competition…even with a “so-so” renovation job:

With one modifcation, DB # 5 goes from “meh” to #1:
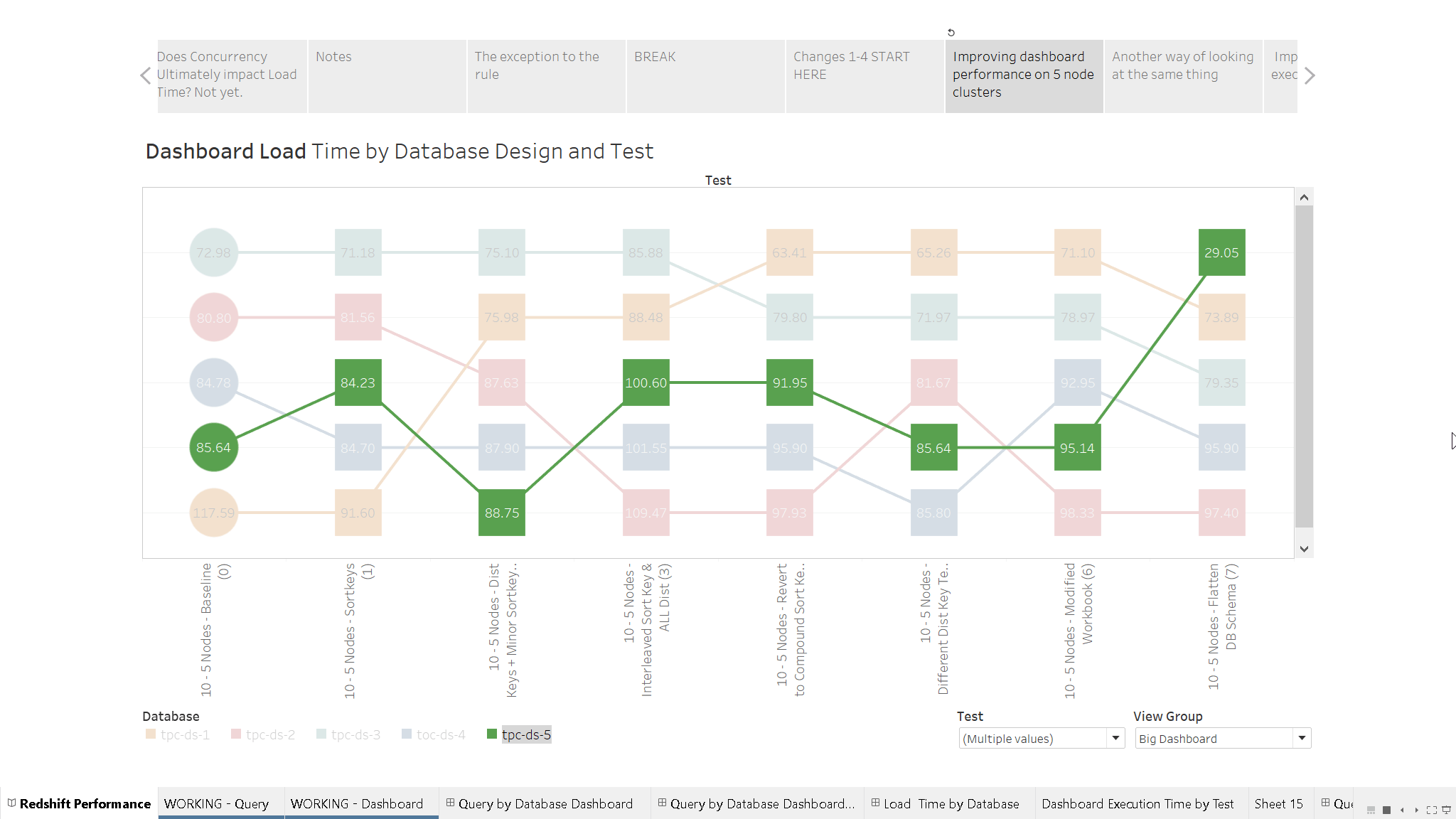
Based on the fact that no changes were made to Database 5 until the final test, it is interesting to see a variation of as much as 10 seconds between tests. Can explain this other than “luck of the draw” and how many times “expensive” vizzes happened to get rendered during a one-ish hour test.
Remember, the unoptimized version of the database and dashboard (database #1) took 117s to render. 29s is pretty darn good.
Let’s compare the queries Tableau now executes against our newly flattened database #5. I’ve also included db1 as a reference:

In the test 10 – 5 Nodes – Flatten DB Schema (7), you can see that Tableau is executing different queries than it did in test 6. They run much faster. As I said, there’s still room for improvement here:

- There are still two LEFT JOINs to dimension tables in the query above
- Looks like cd_education_status is a group leveraging a text field. I might create the group on the numeric KEY of cd_education_status instead, and then alias it to text
Larger Data Sets and Aggregation Tables
180M rows frankly isn’t that much data. Lets compare perceived performance when we move up to 390M rows. I got a bit lazy and dropped back to only using 3 sample databases at larger data volumes: databases 2 and 4 really weren’t doing anything for me, so why bother?
I use database 3 (as you’ll recall it was the “fastest” one out of the box) as a control, while we tinker with databases 1 and 5:

As one would expect, the flattened database 5 is still fastest against 380M rows. Our dashboard is taking a little bit less than 2x the time to complete, however (29s vs 53s). Way too slow. Why don’t we just try “more Redshift” to solve this problem?
“More nodes” will only get you so far. Brute strength can’t really fix bad design – it simply hides it. Temporarily. You’re also doubling your Redshift cost.
In this case, however adding another five nodes works pretty well. At ten nodes, dashboard load time is back to 33s (you can’t see that below, just trust me):

The Elephant
We haven’t discussed the elephant in the room: all this tuning is well and good, but no user is going to accept a dashboard that takes upwards of 30 seconds to render. They just won’t. I sure wouldn’t.
I suspect it would be possible to do additional performance tuning and get this down to 20-25 seconds…but that’s still too slow.
So, let’s create an aggregation (summary) table which rolls up our facts by day. We’ll need to modify dashboard to use this new table as it’s data source in much the same way we did when we implemented the flattened schema. Here is the result, and it’s impressive:

3.69 seconds. Not bad. We’re still running with ten nodes above, but if we dropped down to five, I bet we’d still be under 10 seconds on a “virgin, un-cached” viz exection. That’s acceptible to me.
Next, we’ll pump up fact table rows to just under 3 billion and roll back our aggregate table. We’ll use the flattened database schema which removes many (but not all) of the JOINs in database 5. Database 1 and database 3 remain the same.
We’ll also jack the number of nodes WAY up. I ran two tests: one which utilized thirty-two dc1.large nodes, and another which used two dc.8xlarge nodes. In terms of functional horsepower, both rigs are pretty much equivalent.

The results sure aren’t similar, however. Our “more, smaller nodes” cluster is nearly twice as fast as our “fewer, big nodes” instance. What the hell?
In the Top 10 Things You Must Do article I wrote about a month ago, I mentioned this. Especially when you have a fair number of joins, more nodes are often better than fewer nodes (assuming they deliver the same horsepower in aggregage)
The only test in which the two dc.8xlarges are marginally faster than the thirty-two dc.xlarges is “database 5”.

Why? Most likely it’s the fact that I simplified the schema enough (therefore removing JOINs) to negate the advantage of doing this sort of work on “more nodes”.
Lets finish up by creating an aggregate table on our 3B rows in database 1:

Very fast on both of our “monster” clusters. You’re looking at 5 seconds on the two-node dc1.8xlarge rig and 4 seconds on the thirty-two dc1.xlarges.
We’re done
Thanks for reading, hope this was helpful.
This is quite useful and lots of information to process on this.